library(car)
library(MASS)
library(glmnet)Loading required package: carData
Loading required package: Matrix
Loaded glmnet 4.1-7
library(car)
library(MASS)
library(glmnet)Loading required package: carData
Loading required package: Matrix
Loaded glmnet 4.1-7
”ex4.1.csv” 데이터는 다음의 변수로 이루어져 있다.
• Age : Age in years
• Weight : Weight in lbs
• HtShoes : Height in shoes in cm
• Ht : Height bare foot in cm
• Seated : Seated height in cm
• Arm : lower arm length in cm
• Thigh : Thigh length in cm
• Leg : Lower leg length in cm
• hipcenter : horizontal distance of the midpoint of the hips from a fixed location in the car in mm
“hipcenter”를 예측하기 위한 모형을 적합하려고 한다. 다음 물음에 답하여라.
ex4 <- read.csv("ex4.1.csv")ex4| Age | Weight | HtShoes | Ht | Seated | Arm | Thigh | Leg | hipcenter |
|---|---|---|---|---|---|---|---|---|
| <int> | <int> | <dbl> | <dbl> | <dbl> | <dbl> | <dbl> | <dbl> | <dbl> |
| 46 | 180 | 187.2 | 184.9 | 95.2 | 36.1 | 45.3 | 41.3 | -206.300 |
| 31 | 175 | 167.5 | 165.5 | 83.8 | 32.9 | 36.5 | 35.9 | -178.210 |
| 23 | 100 | 153.6 | 152.2 | 82.9 | 26.0 | 36.6 | 31.0 | -71.673 |
| 19 | 185 | 190.3 | 187.4 | 97.3 | 37.4 | 44.1 | 41.0 | -257.720 |
| 23 | 159 | 178.0 | 174.1 | 93.9 | 29.5 | 40.1 | 36.9 | -173.230 |
| 47 | 170 | 178.7 | 177.0 | 92.4 | 36.0 | 43.2 | 37.4 | -185.150 |
| 30 | 137 | 165.7 | 164.6 | 87.7 | 32.5 | 35.6 | 36.2 | -164.750 |
| 28 | 192 | 185.3 | 182.7 | 96.9 | 35.8 | 39.9 | 43.1 | -270.920 |
| 23 | 150 | 167.6 | 165.0 | 91.4 | 29.4 | 35.5 | 33.4 | -151.780 |
| 29 | 120 | 161.2 | 158.7 | 85.2 | 26.6 | 31.0 | 32.8 | -113.880 |
| 47 | 143 | 171.9 | 169.1 | 87.8 | 32.9 | 39.2 | 36.9 | -196.150 |
| 41 | 107 | 155.7 | 152.5 | 82.9 | 29.6 | 32.7 | 31.1 | -125.550 |
| 51 | 227 | 179.8 | 177.2 | 91.7 | 31.1 | 41.4 | 40.2 | -203.610 |
| 30 | 147 | 164.9 | 162.7 | 88.0 | 27.7 | 33.6 | 33.8 | -163.220 |
| 22 | 178 | 177.2 | 176.4 | 94.1 | 31.1 | 41.0 | 36.6 | -204.110 |
| 67 | 166 | 177.1 | 175.3 | 89.4 | 36.7 | 40.1 | 39.2 | -186.800 |
| 25 | 153 | 173.4 | 171.2 | 85.0 | 33.1 | 45.2 | 38.4 | -228.350 |
| 65 | 113 | 162.6 | 158.7 | 85.2 | 31.1 | 35.7 | 32.5 | -103.850 |
| 22 | 142 | 167.3 | 164.6 | 90.4 | 29.5 | 36.5 | 34.0 | -105.690 |
| 21 | 130 | 172.5 | 170.5 | 89.7 | 29.9 | 35.8 | 35.6 | -137.360 |
| 20 | 145 | 168.4 | 166.3 | 87.9 | 30.3 | 34.6 | 38.5 | -133.080 |
| 33 | 293 | 201.2 | 198.4 | 101.6 | 39.6 | 44.2 | 43.1 | -279.150 |
| 24 | 180 | 187.6 | 185.3 | 92.6 | 34.9 | 39.9 | 41.8 | -185.870 |
| 39 | 117 | 152.8 | 150.2 | 79.4 | 28.9 | 34.8 | 30.2 | -30.950 |
| 58 | 150 | 169.2 | 166.4 | 86.2 | 33.0 | 37.9 | 35.7 | -196.550 |
| 22 | 171 | 184.1 | 181.6 | 95.4 | 33.7 | 41.8 | 39.2 | -205.610 |
| 21 | 125 | 165.8 | 163.4 | 85.0 | 31.0 | 36.4 | 35.3 | -94.502 |
| 23 | 160 | 166.4 | 164.3 | 86.2 | 29.1 | 36.6 | 31.6 | -125.840 |
| 21 | 157 | 177.0 | 175.5 | 91.4 | 34.4 | 41.6 | 36.4 | -222.500 |
| 40 | 115 | 153.8 | 151.6 | 80.3 | 27.5 | 37.6 | 31.7 | -102.200 |
| 59 | 168 | 155.2 | 153.0 | 84.4 | 34.1 | 35.6 | 34.6 | -47.520 |
| 47 | 175 | 176.6 | 175.8 | 90.9 | 34.5 | 45.5 | 37.4 | -183.550 |
| 72 | 186 | 177.7 | 175.0 | 90.1 | 38.3 | 39.7 | 37.7 | -118.050 |
| 34 | 115 | 155.2 | 152.2 | 82.0 | 28.9 | 32.9 | 32.6 | -148.670 |
| 19 | 150 | 172.2 | 169.9 | 89.4 | 34.0 | 39.7 | 38.1 | -268.320 |
| 41 | 121 | 166.3 | 164.1 | 86.5 | 31.5 | 45.1 | 33.8 | -117.000 |
| 21 | 154 | 172.0 | 170.4 | 90.0 | 29.5 | 36.8 | 37.5 | -201.510 |
| 56 | 158 | 173.8 | 171.5 | 90.0 | 36.1 | 39.2 | 35.5 | -176.450 |
변수들 사이의 산점도행렬을 그리고 설명하여라.
pairs(ex4)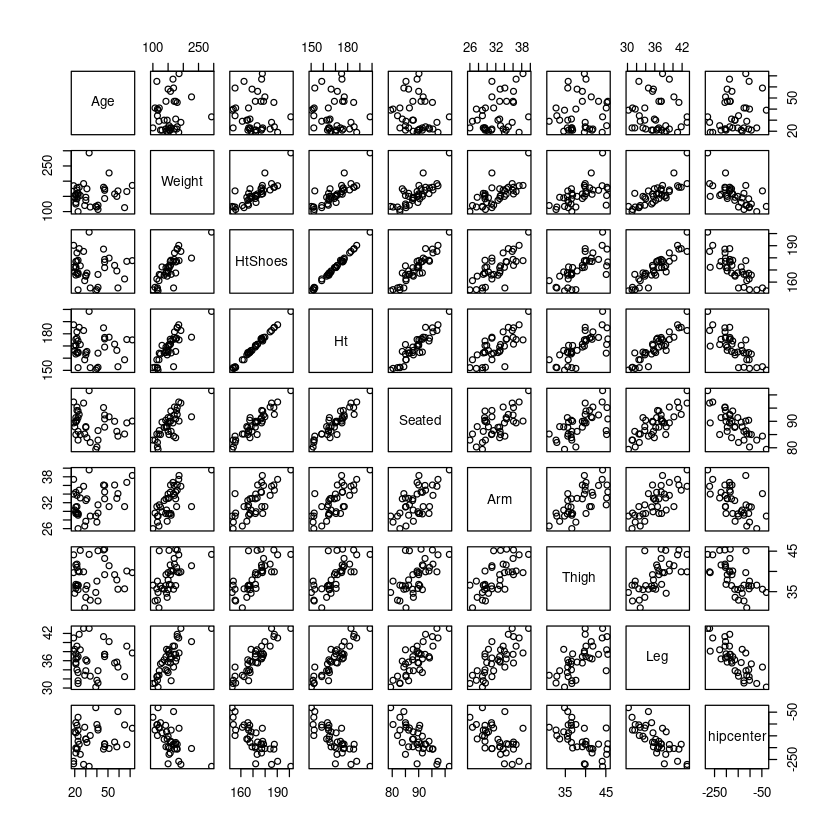
hipcenter와 대부분 음의 상관관계가 있어보이고, Age는 관계가 없어보인다.
다른 설명변수들간에도 서로 양의 상관관계가 있어보인다. Age는 다른 변수들과도 관계가 없어 보임.
변수들 사이의 상관계수를 구하여라. (소수점 둘째자리까지 반올림) 다중공선성이 존재한다고 할 수 있는가?
round(cor(ex4),2)| Age | Weight | HtShoes | Ht | Seated | Arm | Thigh | Leg | hipcenter | |
|---|---|---|---|---|---|---|---|---|---|
| Age | 1.00 | 0.08 | -0.08 | -0.09 | -0.17 | 0.36 | 0.09 | -0.04 | 0.21 |
| Weight | 0.08 | 1.00 | 0.83 | 0.83 | 0.78 | 0.70 | 0.57 | 0.78 | -0.64 |
| HtShoes | -0.08 | 0.83 | 1.00 | 1.00 | 0.93 | 0.75 | 0.72 | 0.91 | -0.80 |
| Ht | -0.09 | 0.83 | 1.00 | 1.00 | 0.93 | 0.75 | 0.73 | 0.91 | -0.80 |
| Seated | -0.17 | 0.78 | 0.93 | 0.93 | 1.00 | 0.63 | 0.61 | 0.81 | -0.73 |
| Arm | 0.36 | 0.70 | 0.75 | 0.75 | 0.63 | 1.00 | 0.67 | 0.75 | -0.59 |
| Thigh | 0.09 | 0.57 | 0.72 | 0.73 | 0.61 | 0.67 | 1.00 | 0.65 | -0.59 |
| Leg | -0.04 | 0.78 | 0.91 | 0.91 | 0.81 | 0.75 | 0.65 | 1.00 | -0.79 |
| hipcenter | 0.21 | -0.64 | -0.80 | -0.80 | -0.73 | -0.59 | -0.59 | -0.79 | 1.00 |
선형회귀모형을 적합하여라. (계수를 추정. 예 : \(\hat y = 3 + 2x\) 이렇게 적어주기)
fit <- lm(hipcenter~., ex4)
summary(fit)
Call:
lm(formula = hipcenter ~ ., data = ex4)
Residuals:
Min 1Q Median 3Q Max
-73.827 -22.833 -3.678 25.017 62.337
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 436.43213 166.57162 2.620 0.0138 *
Age 0.77572 0.57033 1.360 0.1843
Weight 0.02631 0.33097 0.080 0.9372
HtShoes -2.69241 9.75304 -0.276 0.7845
Ht 0.60134 10.12987 0.059 0.9531
Seated 0.53375 3.76189 0.142 0.8882
Arm -1.32807 3.90020 -0.341 0.7359
Thigh -1.14312 2.66002 -0.430 0.6706
Leg -6.43905 4.71386 -1.366 0.1824
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 37.72 on 29 degrees of freedom
Multiple R-squared: 0.6866, Adjusted R-squared: 0.6001
F-statistic: 7.94 on 8 and 29 DF, p-value: 1.306e-05\(\widehat {hipcenter}=436.43+0.78 \widehat{Age} + 0.03 \widehat{Weight} - 2.69 \widehat{HtShoes}+0.60\widehat{Ht}+0.53\widehat{Seated}-1.33\widehat{Arm}-1.14\widehat{Thigh}-6.44\widehat{Leg}\)
위의 선형회귀모형에서 개별 회귀계수의 유의성 검정 결과와 (1),(2)번 결과와 연관지어 설명하여라.
회귀모형의 p-value값은 1.306e-05으로 유의하고 \(R^2\)값도 68%정도로 약간 높은 편이지만 회귀계수는 절편을 제외하고는(절편도..그닥.) 모두 유의하지 않다. 이와 같은 경우는 다중공산성이 존재하기 때문이다.
car 패키지의 vif 함수를 이용하여 각 설명변수의 vif값을 구하여라.
vif(fit)vif의 값이 10이상이면 다중공산성이 있다고 보자.
HtShoes,Ht의 값이 높은 값을 가지며 다중곤상성이 있다.
glmnet 함수를 이용하여 능형회귀모형을 적합하고자 한다.
X <- model.matrix(hipcenter~., ex4)[,-1]
y <- ex4$hipcenterλ 의 값에 따라 회귀계수가 변하는지 그림으로 보여라. (이 때 0 < λ < 100 으로 설정)
ridge.fit<-glmnet(X,y,alpha=0, lambda=seq(0,100,0.1)) ##ridge : alpha=0
plot(ridge.fit, label=TRUE)
abline(h=0, col="grey", lty=2)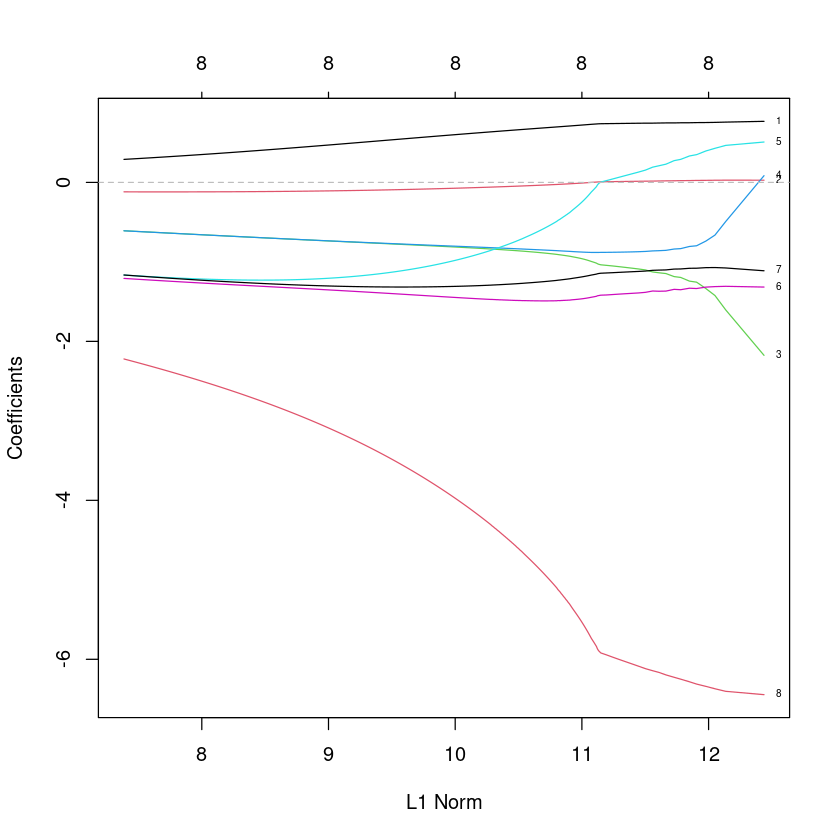
교차검증을 수행하였을 때, MSE를 가장 작게 하는 λ 는 무엇인가?
X <- model.matrix(hipcenter~., ex4)[,-1]
y <- ex4$hipcentercv.fit<-cv.glmnet(X,y,alpha=0,nfolds=length(y))Warning message:
“Option grouped=FALSE enforced in cv.glmnet, since < 3 observations per fold”cv.fit
Call: cv.glmnet(x = X, y = y, nfolds = length(y), alpha = 0)
Measure: Mean-Squared Error
Lambda Index Measure SE Nonzero
min 36.41 78 1442 315.7 8
1se 213.24 59 1750 411.7 8위의 λ에 대한 능형회귀 추정량은 무엇인가?
lam<-cv.fit$lambda.min;lamlog(lam)predict(ridge.fit,type="coefficients",s=lam)9 x 1 sparse Matrix of class "dgCMatrix"
s1
(Intercept) 400.1966209
Age 0.4741535
Weight -0.1060971
HtShoes -0.7390462
Ht -0.7374872
Seated -1.2030446
Arm -1.3553194
Thigh -1.3044858
Leg -3.1112979beta <- predict(ridge.fit,type="coefficients",s=lam)beta9 x 1 sparse Matrix of class "dgCMatrix"
s1
(Intercept) 400.1966209
Age 0.4741535
Weight -0.1060971
HtShoes -0.7390462
Ht -0.7374872
Seated -1.2030446
Arm -1.3553194
Thigh -1.3044858
Leg -3.1112979Hastie와 Tibshirani (1990, p.282)는 척추가 심하게 앞으로 굽어서 척추 교정 수술을 해야하는 척추후만증(kyphosis)에 대한 위험인자를 결정하는 연구를 하였다. 18명의 척추후만증 환자들을 대상으로 수술했을 때의 나이(월)는 각각 12, 15, 42, 52, 59, 73, 82, 91, 96, 105, 114, 120, 121, 128, 130, 139, 139, 157였고, 척추후만증이 없는 22명의 환자의 나이는 1, 1, 2, 8, 11, 18, 22, 31, 37, 61, 72, 81, 97, 112, 118, 127, 131,140, 151, 159, 177, 206으로 조사되었다. 다음 물음에 답하여라.
kyphosisY <-c(12, 15, 42, 52, 59, 73, 82, 91, 96, 105, 114, 120, 121, 128, 130, 139, 139, 157)
kyphosisN <-c(1, 1, 2, 8, 11, 18, 22, 31, 37, 61, 72, 81, 97, 112, 118, 127, 131,140, 151, 159, 177, 206)y <- c(rep(1, length(kyphosisY)), rep(0, length(kyphosisN)))dt <- data.frame(age = c(kyphosisY, kyphosisN), kyphosis = y)dt| age | kyphosis |
|---|---|
| <dbl> | <dbl> |
| 12 | 1 |
| 15 | 1 |
| 42 | 1 |
| 52 | 1 |
| 59 | 1 |
| 73 | 1 |
| 82 | 1 |
| 91 | 1 |
| 96 | 1 |
| 105 | 1 |
| 114 | 1 |
| 120 | 1 |
| 121 | 1 |
| 128 | 1 |
| 130 | 1 |
| 139 | 1 |
| 139 | 1 |
| 157 | 1 |
| 1 | 0 |
| 1 | 0 |
| 2 | 0 |
| 8 | 0 |
| 11 | 0 |
| 18 | 0 |
| 22 | 0 |
| 31 | 0 |
| 37 | 0 |
| 61 | 0 |
| 72 | 0 |
| 81 | 0 |
| 97 | 0 |
| 112 | 0 |
| 118 | 0 |
| 127 | 0 |
| 131 | 0 |
| 140 | 0 |
| 151 | 0 |
| 159 | 0 |
| 177 | 0 |
| 206 | 0 |
나이를 예측변수로 하여 척추후만증에 대한 로지스틱 회귀모형을 적합하라. (모형을 정확하게 기재)
model <- glm(kyphosis ~ age, data = dt, family = binomial())summary(model)
Call:
glm(formula = kyphosis ~ age, family = binomial(), data = dt)
Deviance Residuals:
Min 1Q Median 3Q Max
-1.3126 -1.0907 -0.9482 1.2170 1.4052
Coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept) -0.572693 0.602395 -0.951 0.342
age 0.004296 0.005849 0.734 0.463
(Dispersion parameter for binomial family taken to be 1)
Null deviance: 55.051 on 39 degrees of freedom
Residual deviance: 54.504 on 38 degrees of freedom
AIC: 58.504
Number of Fisher Scoring iterations: 4\(\widehat {kyphosis} = -0.5727 +0.0043 \widehat{age}\)
나이가 유의한 효과를 갖는지를 검정하라.
age의 z-value의 값은 0.734로 0.05보다 크므로 유의하지 않다.
자료에 대한 산점도를 그려라. 단, 척추후만증의 두 수준에서 나이의 분포가 차이가 나는 것을 주목하라.(상자그림 확인)
boxplot(age ~ kyphosis, data = dt, cex.axis = 0.8,
xlab = "Kyphosis", ylab = "Age", col = c("steelblue", "darkorange"))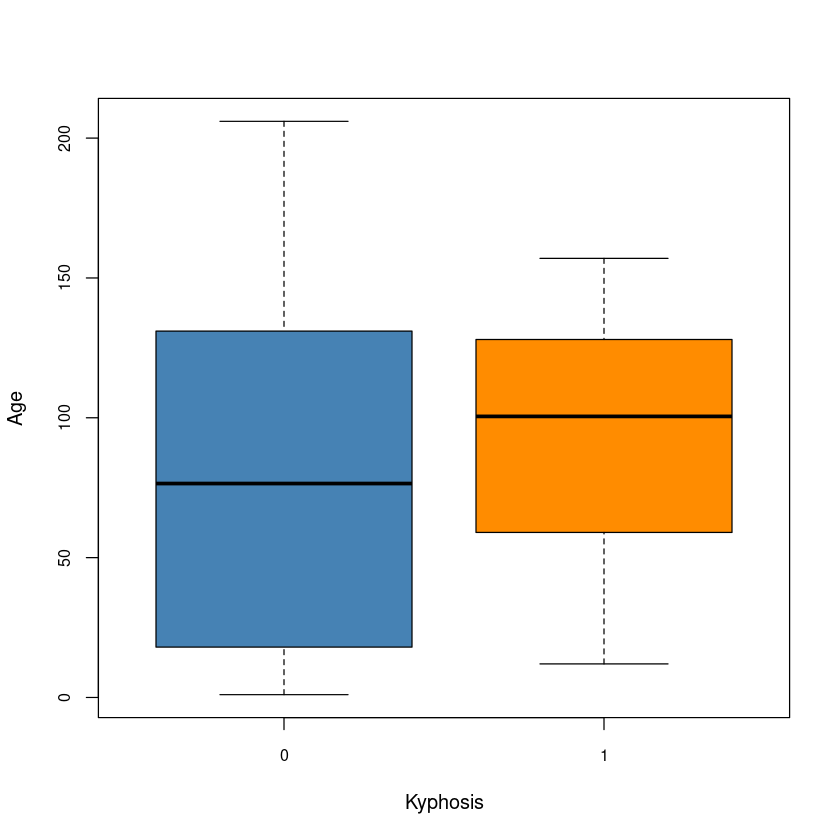
로지스틱 회귀모형
\[logit(Pr(x))= log \dfrac{Pr(y = 1|x)}{1 − Pr(y = 1|x)}= α + β_1x + β_2x^2\]
를 적합시킨 후에 나이의 제곱합에 대한 유의성검정을 하여라
model2 <- glm(kyphosis ~ age + I(age^2), data = dt, family = binomial())
summary(model2)
Call:
glm(formula = kyphosis ~ age + I(age^2), family = binomial(),
data = dt)
Deviance Residuals:
Min 1Q Median 3Q Max
-1.482 -1.009 -0.507 1.012 1.788
Coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept) -2.0462547 0.9943478 -2.058 0.0396 *
age 0.0600398 0.0267808 2.242 0.0250 *
I(age^2) -0.0003279 0.0001564 -2.097 0.0360 *
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
(Dispersion parameter for binomial family taken to be 1)
Null deviance: 55.051 on 39 degrees of freedom
Residual deviance: 48.228 on 37 degrees of freedom
AIC: 54.228
Number of Fisher Scoring iterations: 4\(\widehat {kyphosis} = -2.0462547 + 0.0600398 \widehat{age} - 0.0003279\widehat{age}^2\)
\(\hat β_2\)의 의미를 서술하시오.
x가 한단위 증가하면 성공의 오즈는 e^(beta2)배 만큼 증가한다.
살인사건에 대한 사형선고 여부와 인종사이의 관계를 알아보기 위하여 미국의 한 주의 2000년 이후의 해당 케이스들에 대하여, \(y =\)살인사건으로 기소된 사람에 대한 사형선고 여부(1=예, 0=아니오)를 반응변수로 하고 피고인(D)과 피해자(V)의 인종(1=흑인, 0=백인)를 설명변수로 하는 로지스틱 회귀모형을 적합하였다.적합에 의하여 추정된 추정식이
\[logit(\hat{Pr}(x))= log \dfrac{\hat{Pr}(y = 1|x)}{1 − \hat{Pr}(y = 1|x)}= −2.06 + 0.87D − 2.4V\]
라 한다. 다음은 예측식에 기초한 참과 거짓에 대한 질문이다. 참인지 거짓인지 판단하라. (풀이과정 기재
사형선고에 대한 추정확률은 피고인이 백인(D=0)이고 피해자가 흑인(V=1)일 때 가장 낮다.
Tlogit(Pr(y = 1|x)) = -2.06 + 0.87D - 2.4V 에서
D=0, V=1대입하면
logit(Pr(y = 1|x)) = -2.06 + 0.87(0) - 2.4(1) = -2.06 - 2.4 = -4.46
각 식에 e를 곱해주면
Pr(y = 1|x) = exp(-4.46) / (1 + exp(-4.46))이다.
피고인이 백인이고 피해자가 흑인일때 사형이 선고될 예상 확률이다.
D=0, V=0 넣으면 -2.06
D=1, V=0 넣으면 -1.19
D=1, V=1 넣으면 -3.59
피해자의 인종이 주어져 있을 떄 백인 피고인(D=0)이 사형선고를 받을 오즈의 추정값은 흑인 피고인(D=1)의 오즈의 0.87배이다.
만약 백인 피고인일 경우 D = 1이고 흑인일 경우 D = 0이면 D의 회귀계수의 추정값은 0.87이 아니라 1/0.87 = 1.15가 되었을 것이다.
D의 회귀계수 추정값: 0.87
백인 피고인의 오즈가 흑인 피고인의 오즈의 0.87배절편의 추정값 −2.06은 피고인과 피해자가 백인일 경우(D = V = 0)에 사형선고에 대한 추정확률이다.
D=0,V=0일때의 값이므로 trUE
만약, 백인피해자와 피고인이 500명일 때, 사형선고를 받는 사람에 대해 모형에서 적합된 도수(즉, 추정되는 기대도수)는 \(500e^{−2.06}/(1 + e^{−2.06})\)과 같다.
v=0, D=0이므로 대입해보면,
로짓값
$logit(\hat pr(X)=-2.06+0.87 \times 0 - 2.4 \times 0$
확률
$\hat pr(y=1|X)=e^{-2.06}로짓 l 확률 p라고 놓으면
\(L=ln\dfrac{p}{1-p}\)
역함수 \(p=\dfrac{1}{1+e^{-L}}\)
아래위로 \(e^{-L}\)을 곱해주면 시그모이드 함수가 나옴
\(p=\dfrac{e^{-L}}{e^{-L}+1}\)
기대도수는 여기에다가 인원수 곱하면 됨.
선형회귀모형
\[y_i = β_0 + β_1x_i + ϵ_i, i = 1, 2, · · · , n\]
에서 만약 오차벡터 \(ϵ^⊤ = (ϵ_1, ϵ_2, · · · , ϵ_n)\)의 분산-공분산행렬이
\[Var(\epsilon) = \begin{bmatrix} \sigma_1^2 & 0 & \dots & 0 \\ 0 & \sigma_2^2 & \dots & 0 \\ \dots & \dots & & \dots \\ 0 & 0 & \dots & \sigma_n^2 \end{bmatrix}\]
인 경우 \(β_0\) 와 \(β_1\)의 GLS 추정값을 구하시오. 만약 회귀모형이
\[y_i = β_1x_i + ϵ_i\]
이면 \(β_1\)의 GLS 추정값은 어떻게 되는가?
GLS: \(\hat \beta^*=(X^TV^{-1}X)^{-1}X^TV^{-1}Xy\)
\(E(\hat \beta^*)=(X^TV^{-1}X)^{-1}X^TV^{-1}X \beta=\beta\)
\(Var(\hat \beta^*)=(X^TV^{-1}X)^{-1}V^{-1}V \sigma^2 V^{-1}X(X^TV^{-1}X)^{-1}=\sigma^2(X^TV^{-1}X)^{-1}\)
\(SSE(\hat \beta^*)=(y-X\hat \beta^*)^T V^{-1}(y-X\hat \beta^*)\)
\(y=X \beta + \epsilon\)
\(Var(\epsilon) = \sigma^2 V\)
\(V=KK (K:n \times n)\)
\(K^{-1}y = K^{-1}X \beta + K^{-1} \epsilon\)
\(Var(K^{-1}\epsilon)=K^{-1}V \sigma^2 K^{-1} = K^{-1}KKK^{-1} \sigma^2 = I_n \sigma^2\)
변수변환!
\(y^* = X^*\beta + \epsilon^*\)
\(y^* = K^{-1}y, X^*=K^{-1}X, \epsilon^* = K^{-1}\epsilon\)
\(\widehat \beta = (X^{*T}X^*)^{-1}X^{*T}y^*=(X^TK^{-1}K^{-1}X)^{-1}X^TK^{-1}K^{-1}y\)
\(KK=V, K^{-1}K^{-1}=V^{-1}\)
\(\widehat \beta^{GLS}=(X^TV^{-1}X)^{-1}X^TV^{-1}y\)