해당 강의노트는 전북대학교 김광수교수님 2023-2 고급딥러닝 자료임
## https://www.tensorflow.org/tutorials/keras/regression?hl=ko ## import pathlibimport matplotlib.pyplot as pltimport pandas as pdimport seaborn as snsimport numpy as npimport tensorflow as tffrom tensorflow import kerasfrom tensorflow.keras import layersprint (tf.__version__)
= keras.utils.get_file("auto-mpg.data" , "http://archive.ics.uci.edu/ml/machine-learning-databases/auto-mpg/auto-mpg.data" )
'/root/.keras/datasets/auto-mpg.data'
= ['MPG' ,'Cylinders' ,'Displacement' ,'Horsepower' ,'Weight' ,'Acceleration' , 'Model Year' , 'Origin' ]= pd.read_csv(dataset_path, names= column_names,= "?" , comment= ' \t ' ,= " " , skipinitialspace= True )= raw_dataset.copy()
393
27.0
4
140.0
86.0
2790.0
15.6
82
1
394
44.0
4
97.0
52.0
2130.0
24.6
82
2
395
32.0
4
135.0
84.0
2295.0
11.6
82
1
396
28.0
4
120.0
79.0
2625.0
18.6
82
1
397
31.0
4
119.0
82.0
2720.0
19.4
82
1
= dataset.dropna()= dataset.pop('Origin' )#dataset['USA'] = (origin == 1)*1.0 'Europe' ] = (origin == 2 )* 1.0 'Japan' ] = (origin == 3 )* 1.0
SettingWithCopyWarning:
A value is trying to be set on a copy of a slice from a DataFrame.
Try using .loc[row_indexer,col_indexer] = value instead
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
dataset['USA'] = (origin == 1)*1.0
<ipython-input-5-f05403a9f198>:4: SettingWithCopyWarning:
A value is trying to be set on a copy of a slice from a DataFrame.
Try using .loc[row_indexer,col_indexer] = value instead
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
dataset['Europe'] = (origin == 2)*1.0
<ipython-input-5-f05403a9f198>:5: SettingWithCopyWarning:
A value is trying to be set on a copy of a slice from a DataFrame.
Try using .loc[row_indexer,col_indexer] = value instead
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
dataset['Japan'] = (origin == 3)*1.0
393
27.0
4
140.0
86.0
2790.0
15.6
82
1.0
0.0
0.0
394
44.0
4
97.0
52.0
2130.0
24.6
82
0.0
1.0
0.0
395
32.0
4
135.0
84.0
2295.0
11.6
82
1.0
0.0
0.0
396
28.0
4
120.0
79.0
2625.0
18.6
82
1.0
0.0
0.0
397
31.0
4
119.0
82.0
2720.0
19.4
82
1.0
0.0
0.0
= dataset.sample(frac= 0.8 ,random_state= 0 )= dataset.drop(train_dataset.index)= train_dataset.describe()"MPG" )= train_stats.transpose()
= train_dataset.pop('MPG' )= test_dataset.pop('MPG' )def norm(x):return (x - train_stats['mean' ]) / train_stats['std' ]= norm(train_dataset)= norm(test_dataset)
def build_model():= keras.Sequential([64 , activation= 'relu' , input_shape= [len (train_dataset.keys())]),64 , activation= 'relu' ), # 'linear' instead of 'relu' #layers.Dense(64, activation='relu'), #layers.Dense(64, activation='relu'), 1 ) ])= tf.keras.optimizers.RMSprop(0.001 )compile (loss= 'mse' ,= optimizer,= ['mae' , 'mse' ])return model
= build_model()class PrintDot(keras.callbacks.Callback):def on_epoch_end(self , epoch, logs):if epoch % 100 == 0 : print ('' )print ('.' , end= '' )= 500 = model.fit(= EPOCHS, validation_split = 0.2 , verbose= 0 ,= [PrintDot()])
Model: "sequential_15"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense_53 (Dense) (None, 64) 640
dense_54 (Dense) (None, 64) 4160
dense_55 (Dense) (None, 64) 4160
dense_56 (Dense) (None, 64) 4160
dense_57 (Dense) (None, 1) 65
=================================================================
Total params: 13185 (51.50 KB)
Trainable params: 13185 (51.50 KB)
Non-trainable params: 0 (0.00 Byte)
_________________________________________________________________
....................................................................................................
....................................................................................................
....................................................................................................
....................................................................................................
....................................................................................................
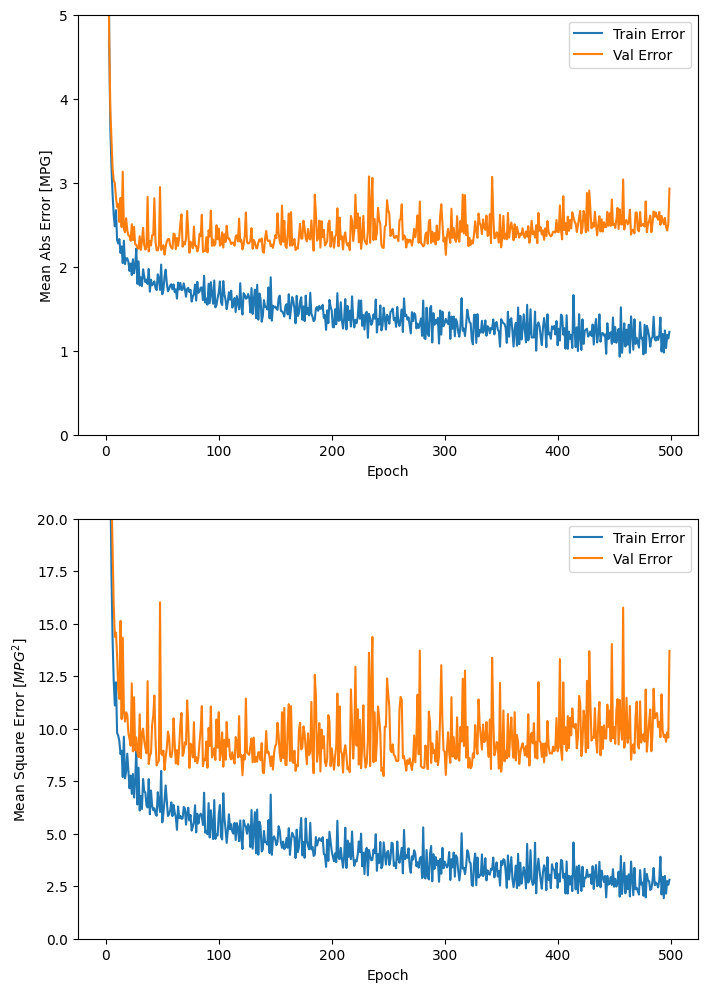
def plot_history(history):= pd.DataFrame(history.history)'epoch' ] = history.epoch= (8 ,12 ))2 ,1 ,1 )'Epoch' )'Mean Abs Error [MPG]' )'epoch' ], hist['mae' ],= 'Train Error' )'epoch' ], hist['val_mae' ],= 'Val Error' )0 ,5 ])2 ,1 ,2 )'Epoch' )'Mean Square Error [$MPG^2$]' )'epoch' ], hist['mse' ],= 'Train Error' )'epoch' ], hist['val_mse' ],= 'Val Error' )0 ,20 ])
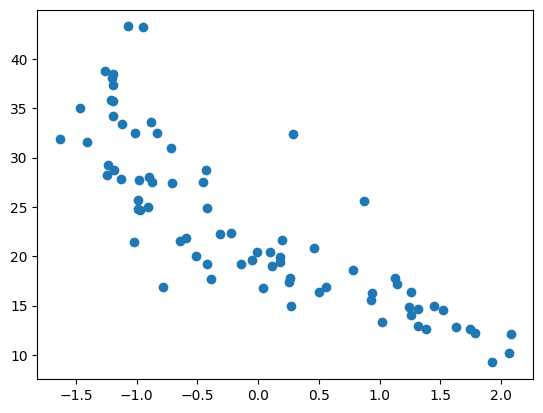
= model.predict(normed_test_data).flatten()= np.array(test_predictions)= np.array(normed_test_data["Weight" ])print ('MSE' , np.mean(yy- test_labels)** 2 )= np.array(np.argsort(xx), dtype= 'int' )print (idx)= xx[idx]= yy[idx]
3/3 [==============================] - 0s 4ms/step
MSE 3.2270409256119708
[ 9 65 44 56 38 24 76 57 74 66 43 45 40 37 67 60 10 52 41 21 13 30 68 3
50 75 34 61 11 64 73 25 27 49 72 77 4 62 23 63 59 22 33 31 18 47 36 8
51 46 48 32 29 69 58 70 28 39 71 16 26 0 55 53 15 54 42 12 14 6 35 20
17 5 19 1 2 7]