import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import networkx as nx
import sklearn
# sklearn
from sklearn import model_selection # split함수이용
from sklearn import ensemble # RF,GBM
from sklearn import metrics
from sklearn.metrics import precision_score, recall_score, f1_score
from sklearn.svm import SVC
from sklearn.ensemble import RandomForestClassifier
from sklearn.naive_bayes import GaussianNB
# gnn
import torch
import torch.nn.functional as F
import torch_geometric
from torch_geometric.nn import GCNConv
import graftimports
def down_sample_textbook(df):
df_majority = df[df.is_fraud==0].copy()
df_minority = df[df.is_fraud==1].copy()
df_maj_dowsampled = sklearn.utils.resample(df_majority, n_samples=len(df_minority), replace=False, random_state=42)
df_downsampled = pd.concat([df_minority, df_maj_dowsampled])
return df_downsampled
def compute_time_difference(group):
n = len(group)
result = []
for i in range(n):
for j in range(n):
time_difference = abs(group.iloc[i].trans_date_trans_time.value - group.iloc[j].trans_date_trans_time.value)
result.append([group.iloc[i].name, group.iloc[j].name, time_difference])
return result
def mask(df):
df_tr,df_test = sklearn.model_selection.train_test_split(df, random_state=42)
N = len(df)
train_mask = [i in df_tr.index for i in range(N)]
test_mask = [i in df_test.index for i in range(N)]
train_mask = np.array(train_mask)
test_mask = np.array(test_mask)
return train_mask, test_mask
def edge_index_selected(edge_index):
theta = edge_index[:,2].mean()
edge_index[:,2] = (np.exp(-edge_index[:,2]/theta) != 1)*(np.exp(-edge_index[:,2]/theta))
edge_index = edge_index.tolist()
mean_ = np.array(edge_index)[:,2].mean()
selected_edges = [(int(row[0]), int(row[1])) for row in edge_index if row[2] > mean_]
edge_index_selected = torch.tensor(selected_edges, dtype=torch.long).t()
return edge_index_selected
fraudTrain = pd.read_csv("~/Desktop/fraudTrain.csv").iloc[:,1:]# # fraudTrain = fraudTrain.assign(trans_date_trans_time= list(map(lambda x: pd.to_datetime(x), fraudTrain.trans_date_trans_time)))
# fraudTrain = fraudTrain.assign(
# trans_date_trans_time= fraudTrain.trans_date_trans_time.apply(pd.to_datetime)
# )
fraudTrain = pd.read_pickle('temp.pkl')데이터정리
_df1 = fraudTrain[fraudTrain["is_fraud"] == 0].sample(frac=0.20, random_state=42)
_df2 = fraudTrain[fraudTrain["is_fraud"] == 1]
df02 = pd.concat([_df1,_df2])
df02.shape(214520, 22)df50 = down_sample_textbook(df02)
df50 = df50.reset_index()
df50.shape(12012, 23)tr/test
mask(df50)
train_mask, test_mask = mask(df50)pdf! (node10) cc_num = 4.503100e+18
c_sample = 4.503100e+18groups = df50[df50['cc_num'] == c_sample]
def compute_time_difference(group):
n = len(group)
result = []
for i in range(n):
for j in range(n):
time_difference = abs(group.iloc[i].trans_date_trans_time.value - group.iloc[j].trans_date_trans_time.value)
result.append([group.iloc[i].name, group.iloc[j].name, time_difference])
return result
edge_index = compute_time_difference(groups)
edge_index = (np.array(edge_index)).astype(np.float64)
edge_index = np.array(edge_index)[np.array(edge_index)[:,0] != np.array(edge_index)[:,1]]
theta = edge_index[:,2].mean()
edge_index[:,2] = (np.exp(-edge_index[:,2]/theta*9)!= 1)*(np.exp(-edge_index[:,2]/theta*9))
edge_index = edge_index.tolist()
selected_indices1 = df50[df50['cc_num'] == c_sample].index
is_fraud_values1 = df50.loc[selected_indices1, 'is_fraud'].tolist()
g = torch_geometric.data.Data(
edge_index = np.array(edge_index)[:,:2],
edge_attr = np.array(edge_index)[:,-1], # weight
x = df50.loc[selected_indices1, 'amt'].tolist(),
y = df50.loc[selected_indices1, 'is_fraud'].tolist()
)
unique_nodes = set(g.edge_index.reshape(-1).tolist())
dict_map = {n:i for i,n in enumerate(unique_nodes)}
source, target = np.array(edge_index)[:,0], np.array(edge_index)[:,1]
edge_index_selected2 = torch.tensor([[dict_map[s] for s in source.tolist()],[dict_map[t] for t in target.tolist()]])
g = torch_geometric.data.Data(
edge_index = edge_index_selected2,
edge_attr = np.array(edge_index)[:,-1],
x = df50.loc[selected_indices1, 'amt'].tolist(),
y = df50.loc[selected_indices1, 'is_fraud'].tolist()
)
dr_opts = {
'output_size': (150,150),
'edge_marker_size': 1,
#'output':"ten-nodes.pdf",
}
graft.graph.plot_undirected_weighted(
g,
node_color=g.y,
node_size=g.x,
edge_weight_text=False,
edge_weight_width_scale=3.0,
draw_options= dr_opts,
)
/home/coco/anaconda3/envs/test/lib/python3.10/site-packages/torch_geometric/data/storage.py:327: UserWarning: Unable to accurately infer 'num_nodes' from the attribute set '{'edge_attr', 'y', 'edge_index', 'x'}'. Please explicitly set 'num_nodes' as an attribute of 'data' to suppress this warning
warnings.warn(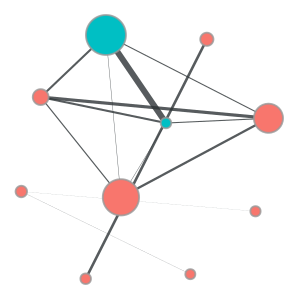
pdf! (node10) cc_num = 4.809700e+12
c_sample = 4.809700e+12
groups = df50[df50['cc_num'] == c_sample]
def compute_time_difference(group):
n = len(group)
result = []
for i in range(n):
for j in range(n):
time_difference = abs(group.iloc[i].trans_date_trans_time.value - group.iloc[j].trans_date_trans_time.value)
result.append([group.iloc[i].name, group.iloc[j].name, time_difference])
return result
edge_index = compute_time_difference(groups)
edge_index = (np.array(edge_index)).astype(np.float64)
edge_index = np.array(edge_index)[np.array(edge_index)[:,0] != np.array(edge_index)[:,1]]
theta = edge_index[:,2].mean()
edge_index[:,2] = (np.exp(-edge_index[:,2]/theta*9)!= 1)*(np.exp(-edge_index[:,2]/theta*9))
edge_index = edge_index.tolist()
selected_indices1 = df50[df50['cc_num'] == c_sample].index
is_fraud_values1 = df50.loc[selected_indices1, 'is_fraud'].tolist()
g = torch_geometric.data.Data(
edge_index = np.array(edge_index)[:,:2],
edge_attr = np.array(edge_index)[:,-1], # weight
x = df50.loc[selected_indices1, 'amt'].tolist(),
y = df50.loc[selected_indices1, 'is_fraud'].tolist()
)
unique_nodes = set(g.edge_index.reshape(-1).tolist())
dict_map = {n:i for i,n in enumerate(unique_nodes)}
source, target = np.array(edge_index)[:,0], np.array(edge_index)[:,1]
edge_index_selected2 = torch.tensor([[dict_map[s] for s in source.tolist()],[dict_map[t] for t in target.tolist()]])
g = torch_geometric.data.Data(
edge_index = edge_index_selected2,
edge_attr = np.array(edge_index)[:,-1],
x = df50.loc[selected_indices1, 'amt'].tolist(),
y = df50.loc[selected_indices1, 'is_fraud'].tolist()
)
dr_opts = {
'output_size': (150,150),
'edge_marker_size': 1,
#'output':"ten-nodes.pdf",
}
graft.graph.plot_undirected_weighted(
g,
node_color=g.y,
node_size=g.x,
edge_weight_text=False,
edge_weight_width_scale=3.0,
draw_options= dr_opts,
)
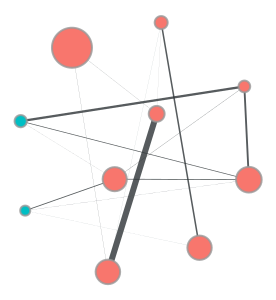
pdf! (node10) cc_num = 6.511350e+15
c_sample = 6.511350e+15
groups = df50[df50['cc_num'] == c_sample]
def compute_time_difference(group):
n = len(group)
result = []
for i in range(n):
for j in range(n):
time_difference = abs(group.iloc[i].trans_date_trans_time.value - group.iloc[j].trans_date_trans_time.value)
result.append([group.iloc[i].name, group.iloc[j].name, time_difference])
return result
edge_index = compute_time_difference(groups)
edge_index = (np.array(edge_index)).astype(np.float64)
edge_index = np.array(edge_index)[np.array(edge_index)[:,0] != np.array(edge_index)[:,1]]
theta = edge_index[:,2].mean()
edge_index[:,2] = (np.exp(-edge_index[:,2]/theta*9)!= 1)*(np.exp(-edge_index[:,2]/theta*9))
edge_index = edge_index.tolist()
selected_indices1 = df50[df50['cc_num'] == c_sample].index
is_fraud_values1 = df50.loc[selected_indices1, 'is_fraud'].tolist()
g = torch_geometric.data.Data(
edge_index = np.array(edge_index)[:,:2],
edge_attr = np.array(edge_index)[:,-1], # weight
x = df50.loc[selected_indices1, 'amt'].tolist(),
y = df50.loc[selected_indices1, 'is_fraud'].tolist()
)
unique_nodes = set(g.edge_index.reshape(-1).tolist())
dict_map = {n:i for i,n in enumerate(unique_nodes)}
source, target = np.array(edge_index)[:,0], np.array(edge_index)[:,1]
edge_index_selected2 = torch.tensor([[dict_map[s] for s in source.tolist()],[dict_map[t] for t in target.tolist()]])
g = torch_geometric.data.Data(
edge_index = edge_index_selected2,
edge_attr = np.array(edge_index)[:,-1],
x = df50.loc[selected_indices1, 'amt'].tolist(),
y = df50.loc[selected_indices1, 'is_fraud'].tolist()
)
dr_opts = {
'output_size': (150,150),
'edge_marker_size': 1,
# 'output':"ten-nodes.pdf",
}
graft.graph.plot_undirected_weighted(
g,
node_color=g.y,
node_size=g.x,
edge_weight_text=False,
edge_weight_width_scale=3.0,
draw_options= dr_opts,
)
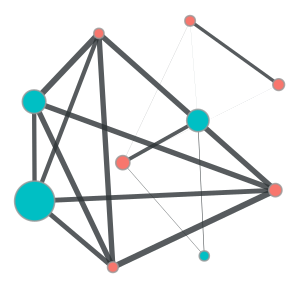
pdf! (node10) cc_num = 5.020500e+11
c_sample = 5.020500e+11
groups = df50[df50['cc_num'] == c_sample]
def compute_time_difference(group):
n = len(group)
result = []
for i in range(n):
for j in range(n):
time_difference = abs(group.iloc[i].trans_date_trans_time.value - group.iloc[j].trans_date_trans_time.value)
result.append([group.iloc[i].name, group.iloc[j].name, time_difference])
return result
edge_index = compute_time_difference(groups)
edge_index = (np.array(edge_index)).astype(np.float64)
edge_index = np.array(edge_index)[np.array(edge_index)[:,0] != np.array(edge_index)[:,1]]
theta = edge_index[:,2].mean()
edge_index[:,2] = (np.exp(-edge_index[:,2]/theta*9)!= 1)*(np.exp(-edge_index[:,2]/theta*9))
edge_index = edge_index.tolist()
selected_indices1 = df50[df50['cc_num'] == c_sample].index
is_fraud_values1 = df50.loc[selected_indices1, 'is_fraud'].tolist()
g = torch_geometric.data.Data(
edge_index = np.array(edge_index)[:,:2],
edge_attr = np.array(edge_index)[:,-1], # weight
x = df50.loc[selected_indices1, 'amt'].tolist(),
y = df50.loc[selected_indices1, 'is_fraud'].tolist()
)
unique_nodes = set(g.edge_index.reshape(-1).tolist())
dict_map = {n:i for i,n in enumerate(unique_nodes)}
source, target = np.array(edge_index)[:,0], np.array(edge_index)[:,1]
edge_index_selected2 = torch.tensor([[dict_map[s] for s in source.tolist()],[dict_map[t] for t in target.tolist()]])
g = torch_geometric.data.Data(
edge_index = edge_index_selected2,
edge_attr = np.array(edge_index)[:,-1],
x = df50.loc[selected_indices1, 'amt'].tolist(),
y = df50.loc[selected_indices1, 'is_fraud'].tolist()
)
dr_opts = {
'output_size': (150,150),
'edge_marker_size': 1,
#'output':"ten-nodes.pdf",
}
graft.graph.plot_undirected_weighted(
g,
node_color=g.y,
node_size=g.x,
edge_weight_text=False,
edge_weight_width_scale=3.0,
draw_options= dr_opts,
)
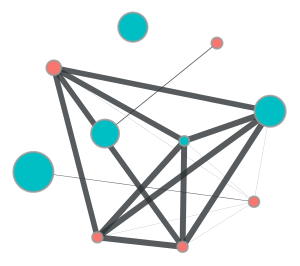
pdf! (node20) cc_num = 2.720010e+15
c_sample = 2.720010e+15groups = df50[df50['cc_num'] == c_sample]
def compute_time_difference(group):
n = len(group)
result = []
for i in range(n):
for j in range(n):
time_difference = abs(group.iloc[i].trans_date_trans_time.value - group.iloc[j].trans_date_trans_time.value)
result.append([group.iloc[i].name, group.iloc[j].name, time_difference])
return result
edge_index = compute_time_difference(groups)
edge_index = (np.array(edge_index)).astype(np.float64)
edge_index = np.array(edge_index)[np.array(edge_index)[:,0] != np.array(edge_index)[:,1]]
theta = edge_index[:,2].mean()
edge_index[:,2] = (np.exp(-edge_index[:,2]/theta)!= 1)*(np.exp(-edge_index[:,2]/theta))
edge_index = edge_index.tolist()
selected_indices1 = df50[df50['cc_num'] == c_sample].index
is_fraud_values1 = df50.loc[selected_indices1, 'is_fraud'].tolist()
g = torch_geometric.data.Data(
edge_index = np.array(edge_index)[:,:2],
edge_attr = np.array(edge_index)[:,-1], # weight
x = df50.loc[selected_indices1, 'amt'].tolist(),
y = df50.loc[selected_indices1, 'is_fraud'].tolist()
)
unique_nodes = set(g.edge_index.reshape(-1).tolist())
dict_map = {n:i for i,n in enumerate(unique_nodes)}
source, target = np.array(edge_index)[:,0], np.array(edge_index)[:,1]
edge_index_selected2 = torch.tensor([[dict_map[s] for s in source.tolist()],[dict_map[t] for t in target.tolist()]])
g = torch_geometric.data.Data(
edge_index = edge_index_selected2,
edge_attr = np.array(edge_index)[:,-1],
x = df50.loc[selected_indices1, 'amt'].tolist(),
y = df50.loc[selected_indices1, 'is_fraud'].tolist()
)
dr_opts = {
'output_size': (500,500),
'edge_marker_size': 1,
#'output':"ten-nodes.pdf",
}
graft.graph.plot_undirected_weighted(
g,
node_color=g.y,
node_size=g.x,
edge_weight_text=False,
draw_options= dr_opts,
)
