import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import networkx as nx
import sklearn
# sklearn
from sklearn import model_selection # split함수이용
from sklearn import ensemble # RF,GBM
from sklearn import metrics
from sklearn.metrics import precision_score, recall_score, f1_score
from sklearn.svm import SVC
from sklearn.ensemble import RandomForestClassifier
from sklearn.naive_bayes import GaussianNB
# gnn
import torch
import torch.nn.functional as F
import torch_geometric
from torch_geometric.nn import GCNConv
imports
import graftdef down_sample_textbook(df):
df_majority = df[df.is_fraud==0].copy()
df_minority = df[df.is_fraud==1].copy()
df_maj_dowsampled = sklearn.utils.resample(df_majority, n_samples=len(df_minority), replace=False, random_state=42)
df_downsampled = pd.concat([df_minority, df_maj_dowsampled])
return df_downsampled
def compute_time_difference(group):
n = len(group)
result = []
for i in range(n):
for j in range(n):
time_difference = abs(group.iloc[i].trans_date_trans_time.value - group.iloc[j].trans_date_trans_time.value)
result.append([group.iloc[i].name, group.iloc[j].name, time_difference])
return result
def mask(df):
df_tr,df_test = sklearn.model_selection.train_test_split(df, random_state=42)
N = len(df)
train_mask = [i in df_tr.index for i in range(N)]
test_mask = [i in df_test.index for i in range(N)]
train_mask = np.array(train_mask)
test_mask = np.array(test_mask)
return train_mask, test_mask
def edge_index_selected(edge_index):
theta = edge_index[:,2].mean()
edge_index[:,2] = (np.exp(-edge_index[:,2]/theta) != 1)*(np.exp(-edge_index[:,2]/theta))
edge_index = edge_index.tolist()
mean_ = np.array(edge_index)[:,2].mean()
selected_edges = [(int(row[0]), int(row[1])) for row in edge_index if row[2] > mean_]
edge_index_selected = torch.tensor(selected_edges, dtype=torch.long).t()
return edge_index_selected
fraudTrain = pd.read_csv("~/Desktop/fraudTrain.csv").iloc[:,1:]len(set(fraudTrain['cc_num']))943len(set(fraudTrain['merchant']))693# # fraudTrain = fraudTrain.assign(trans_date_trans_time= list(map(lambda x: pd.to_datetime(x), fraudTrain.trans_date_trans_time)))
# fraudTrain = fraudTrain.assign(
# trans_date_trans_time= fraudTrain.trans_date_trans_time.apply(pd.to_datetime)
# )
fraudTrain = pd.read_pickle('temp.pkl')데이터정리
_df1 = fraudTrain[fraudTrain["is_fraud"] == 0].sample(frac=0.20, random_state=42)
_df2 = fraudTrain[fraudTrain["is_fraud"] == 1]
df02 = pd.concat([_df1,_df2])
df02.shape(214520, 22)df50 = down_sample_textbook(df02)
df50 = df50.reset_index()
df50.shape(12012, 23)tr/test
mask(df50)
train_mask, test_mask = mask(df50)분석 1(GCN): amt
# x = torch.tensor(df50['amt'], dtype=torch.float).reshape(-1,1)
# y = torch.tensor(df50['is_fraud'],dtype=torch.int64)
# data = torch_geometric.data.Data(x=x, edge_index = edge_index_selected, y=y, train_mask = train_mask, test_mask = test_mask)
# data
# torch.manual_seed(202250926)
# class GCN2(torch.nn.Module):
# def __init__(self):
# super().__init__()
# self.conv1 = GCNConv(1, 32)
# self.conv2 = GCNConv(32,2)
# def forward(self, data):
# x, edge_index = data.x, data.edge_index
# x = self.conv1(x, edge_index)
# x = F.relu(x)
# x = F.dropout(x, training=self.training)
# x = self.conv2(x, edge_index)
# return F.log_softmax(x, dim=1)
# X = (data.x[data.train_mask]).numpy()
# XX = (data.x[data.test_mask]).numpy()
# y = (data.y[data.train_mask]).numpy()
# yy = (data.y[data.test_mask]).numpy()
# model = GCN2()
# optimizer = torch.optim.Adam(model.parameters(), lr=0.01, weight_decay=5e-4)
# model.train()
# for epoch in range(400):
# optimizer.zero_grad()
# out = model(data)
# loss = F.nll_loss(out[data.train_mask], data.y[data.train_mask])
# loss.backward()
# optimizer.step()
# model.eval()
# pred = model(data).argmax(dim=1)
# yyhat = pred[data.test_mask]
# metrics = [sklearn.metrics.accuracy_score,
# sklearn.metrics.precision_score,
# sklearn.metrics.recall_score,
# sklearn.metrics.f1_score]
# _results1= pd.DataFrame({m.__name__:[m(yy,yyhat).round(6)] for m in metrics},index=['분석1'])
# _results1# x = torch.tensor(df50['amt'], dtype=torch.float).reshape(-1,1)
# y = torch.tensor(df50['is_fraud'],dtype=torch.int64)
# data = torch_geometric.data.Data(x=x, edge_index = edge_index_selected, y=y, train_mask = train_mask, test_mask = test_mask)
# dataunweighted graph
cc_num_counts = df50['cc_num'].value_counts()
cc_num_10_nodes = cc_num_counts[cc_num_counts == 10].index.tolist()cc10 = df50[(df50['cc_num'].isin(cc_num_10_nodes))]cc10.groupby("cc_num")['is_fraud'].sum().sort_values()cc_num
4.958590e+18 0
4.855490e+18 0
3.573030e+15 0
2.254800e+15 0
4.170690e+15 0
4.708990e+15 0
3.750830e+14 0
6.011400e+15 0
2.296010e+15 0
3.023880e+13 0
3.524570e+15 0
4.783230e+12 0
4.623560e+12 0
6.596740e+15 0
6.763730e+11 0
4.761400e+18 0
3.019960e+13 0
4.809700e+12 2
4.503100e+18 2
6.511350e+15 4
5.020500e+11 5
6.593250e+15 6
6.523180e+15 7
4.996260e+15 7
6.528910e+15 7
3.554850e+15 7
2.131140e+14 7
2.274910e+15 7
3.636050e+13 7
6.304130e+11 8
4.756040e+18 8
4.605900e+12 8
6.502200e+15 8
5.018280e+11 8
4.228410e+15 8
3.772650e+14 8
4.670610e+15 8
4.358140e+18 9
4.209700e+18 9
4.824020e+15 9
6.011200e+15 9
3.462080e+14 9
3.529790e+15 10
1.800380e+14 10
4.669560e+15 10
4.844240e+12 10
3.756230e+14 10
4.110270e+18 10
4.162870e+18 10
4.257110e+18 10
5.144040e+15 10
4.457490e+12 10
2.295960e+15 10
3.452260e+14 10
3.542830e+15 10
Name: is_fraud, dtype: int64c_sample = 4.809700e+12groups = df50[df50['cc_num'] == c_sample]
def compute_time_difference(group):
n = len(group)
result = []
for i in range(n):
for j in range(n):
time_difference = abs(group.iloc[i].trans_date_trans_time.value - group.iloc[j].trans_date_trans_time.value)
result.append([group.iloc[i].name, group.iloc[j].name, time_difference])
return resultedge_index = compute_time_difference(groups)
edge_index = (np.array(edge_index)).astype(np.float64)
theta = edge_index[:,2].mean()
edge_index[:,2] = (np.exp(-edge_index[:,2]/theta)!= 1)*(np.exp(-edge_index[:,2]/theta))
edge_index = edge_index.tolist()
mean_ = np.array(edge_index)[:,2].mean()
selected_edges = [(int(row[0]), int(row[1])) for row in edge_index if row[2] > mean_]
edge_index_selected = torch.tensor(selected_edges, dtype=torch.long).t()
edge_index_selected.shapetorch.Size([2, 42])selected_indices1 = df50[df50['cc_num'] == c_sample].index
is_fraud_values1 = df50.loc[selected_indices1, 'is_fraud'].tolist()
# 두 번째 데이터 선택
# selected_indices2 = df50[df50['cc_num'] == 4.2929e+18].index
# is_fraud_values2 = df50.loc[selected_indices2, 'is_fraud'].tolist()
x = df50.loc[selected_indices1, 'amt'].tolist()
y = df50.loc[selected_indices1, 'is_fraud'].tolist()y[1, 1, 0, 0, 0, 0, 0, 0, 0, 0]g = torch_geometric.data.Data(
edge_index = edge_index_selected,
x = df50.loc[selected_indices1, 'amt'].tolist(),
y = df50.loc[selected_indices1, 'is_fraud'].tolist()
)g = torch_geometric.data.Data(
edge_index = edge_index_selected,
x = df50.loc[selected_indices1, 'amt'].tolist(),
y = df50.loc[selected_indices1, 'is_fraud'].tolist()
)unique_nodes = set(g.edge_index.reshape(-1).tolist())
dict_map = {n:i for i,n in enumerate(unique_nodes)}
source, target = edge_index_selected
edge_index_selected2 = torch.tensor([[dict_map[s] for s in source.tolist()],[dict_map[t] for t in target.tolist()]])edge_index_selectedtensor([[ 4450, 4450, 4450, 4450, 4462, 4462, 4462, 4462, 7320, 7320,
7936, 7936, 7936, 7936, 7936, 7936, 8128, 8128, 8128, 8128,
9654, 9654, 9654, 9654, 9668, 9668, 9668, 9668, 9668, 10079,
10079, 10079, 10079, 11078, 11078, 11078, 11078, 11078, 11177, 11177,
11177, 11177],
[ 4462, 7320, 9668, 10079, 4450, 7320, 9668, 10079, 4450, 4462,
8128, 9654, 9668, 10079, 11078, 11177, 7936, 9654, 11078, 11177,
7936, 8128, 11078, 11177, 4450, 4462, 7936, 10079, 11078, 4450,
4462, 7936, 9668, 7936, 8128, 9654, 9668, 11177, 7936, 8128,
9654, 11078]])g = torch_geometric.data.Data(
edge_index = edge_index_selected2,
x = df50.loc[selected_indices1, 'amt'].tolist(),
y = df50.loc[selected_indices1, 'is_fraud'].tolist()
)g.y[1, 1, 0, 0, 0, 0, 0, 0, 0, 0]edge_index_selected2tensor([[2, 2, 2, 2, 6, 6, 6, 6, 8, 8, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 7, 7, 7, 7,
3, 3, 3, 3, 3, 9, 9, 9, 9, 4, 4, 4, 4, 4, 5, 5, 5, 5],
[6, 8, 3, 9, 2, 8, 3, 9, 2, 6, 1, 7, 3, 9, 4, 5, 0, 7, 4, 5, 0, 1, 4, 5,
2, 6, 0, 9, 4, 2, 6, 0, 3, 0, 1, 7, 3, 5, 0, 1, 7, 4]])g.y[1, 1, 0, 0, 0, 0, 0, 0, 0, 0]g.x[8.32, 17.08, 31.73, 65.4, 64.53, 70.88, 66.18, 15.09, 127.96, 20.28]dr_opts = {
'output_size': (500,500)
}
graft.graph.plot_undirected_unweighted(
g,
node_color=g.y,
node_size=g.x,
draw_options= dr_opts
)/home/coco/anaconda3/envs/test/lib/python3.10/site-packages/torch_geometric/data/storage.py:327: UserWarning: Unable to accurately infer 'num_nodes' from the attribute set '{'y', 'edge_index', 'x'}'. Please explicitly set 'num_nodes' as an attribute of 'data' to suppress this warning
warnings.warn(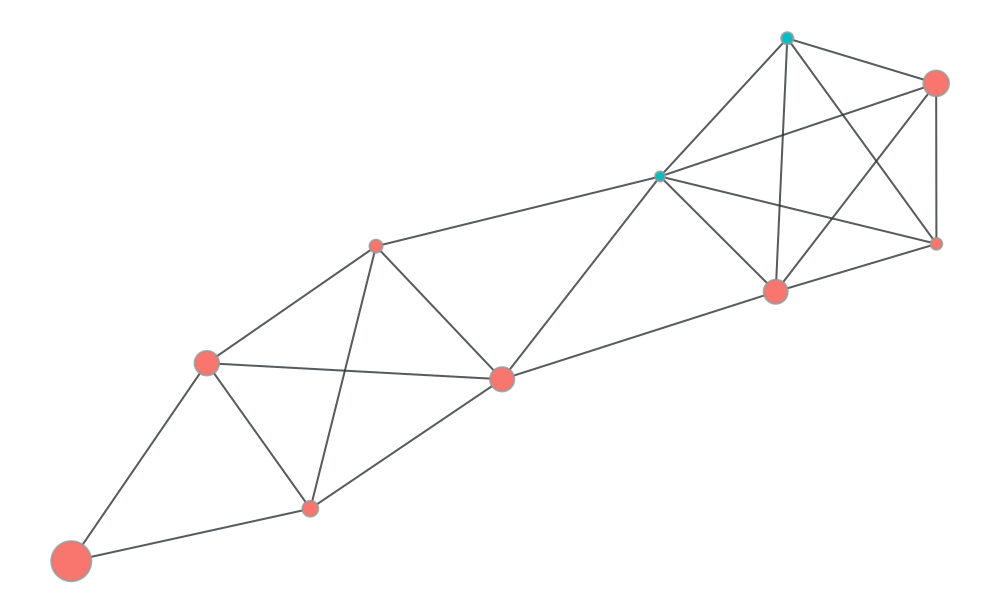
c_sample = 4.503100e+18groups = df50[df50['cc_num'] == c_sample]
def compute_time_difference(group):
n = len(group)
result = []
for i in range(n):
for j in range(n):
time_difference = abs(group.iloc[i].trans_date_trans_time.value - group.iloc[j].trans_date_trans_time.value)
result.append([group.iloc[i].name, group.iloc[j].name, time_difference])
return result
edge_index = compute_time_difference(groups)
edge_index = (np.array(edge_index)).astype(np.float64)
theta = edge_index[:,2].mean()
edge_index[:,2] = (np.exp(-edge_index[:,2]/theta)!= 1)*(np.exp(-edge_index[:,2]/theta))
edge_index = edge_index.tolist()
mean_ = np.array(edge_index)[:,2].mean()
selected_edges = [(int(row[0]), int(row[1])) for row in edge_index if row[2] > mean_]
edge_index_selected = torch.tensor(selected_edges, dtype=torch.long).t()
edge_index_selected.shape
selected_indices1 = df50[df50['cc_num'] == c_sample].index
is_fraud_values1 = df50.loc[selected_indices1, 'is_fraud'].tolist()
# 두 번째 데이터 선택
# selected_indices2 = df50[df50['cc_num'] == 4.2929e+18].index
# is_fraud_values2 = df50.loc[selected_indices2, 'is_fraud'].tolist()
x = df50.loc[selected_indices1, 'amt'].tolist()
y = df50.loc[selected_indices1, 'is_fraud'].tolist()
g = torch_geometric.data.Data(
edge_index = edge_index_selected,
x = df50.loc[selected_indices1, 'amt'].tolist(),
y = df50.loc[selected_indices1, 'is_fraud'].tolist()
)
unique_nodes = set(g.edge_index.reshape(-1).tolist())
dict_map = {n:i for i,n in enumerate(unique_nodes)}
source, target = edge_index_selected
edge_index_selected2 = torch.tensor([[dict_map[s] for s in source.tolist()],[dict_map[t] for t in target.tolist()]])
g = torch_geometric.data.Data(
edge_index = edge_index_selected2,
x = df50.loc[selected_indices1, 'amt'].tolist(),
y = df50.loc[selected_indices1, 'is_fraud'].tolist()
)
dr_opts = {
'output_size': (500,500)
}
graft.graph.plot_undirected_unweighted(
g,
node_color=g.y,
node_size=g.x,
draw_options= dr_opts
)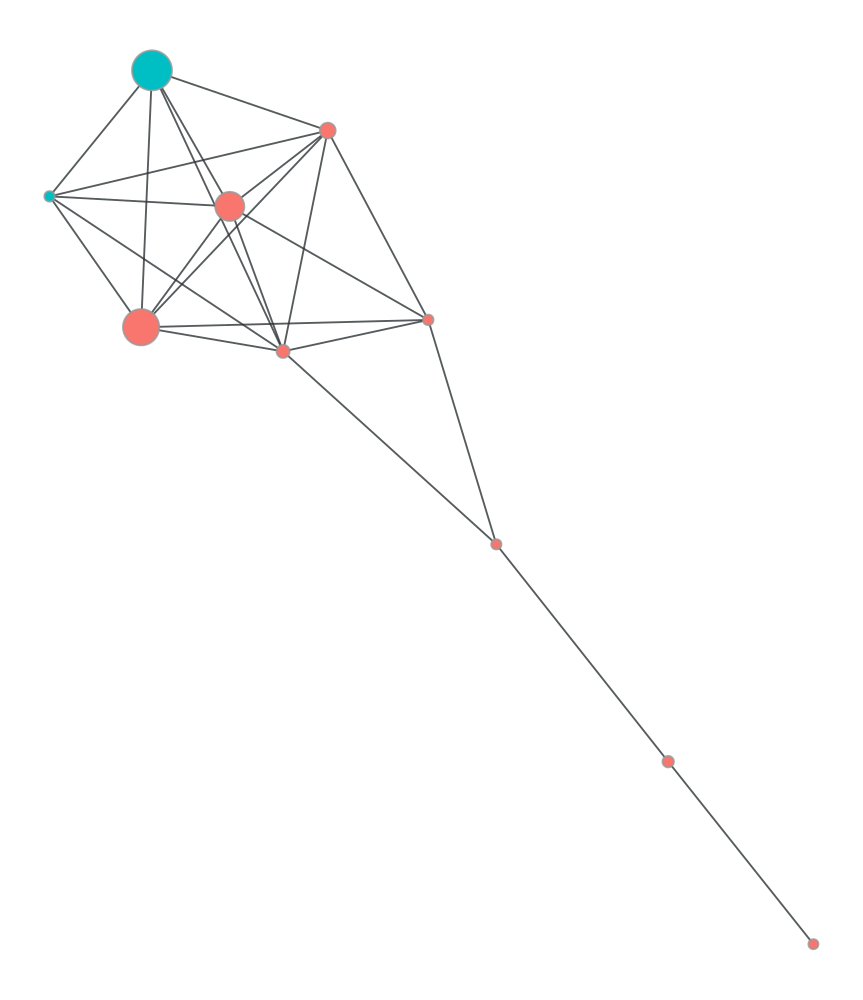
c_sample = 6.511350e+15groups = df50[df50['cc_num'] == c_sample]
def compute_time_difference(group):
n = len(group)
result = []
for i in range(n):
for j in range(n):
time_difference = abs(group.iloc[i].trans_date_trans_time.value - group.iloc[j].trans_date_trans_time.value)
result.append([group.iloc[i].name, group.iloc[j].name, time_difference])
return result
edge_index = compute_time_difference(groups)
edge_index = (np.array(edge_index)).astype(np.float64)
theta = edge_index[:,2].mean()
edge_index[:,2] = (np.exp(-edge_index[:,2]/theta)!= 1)*(np.exp(-edge_index[:,2]/theta))
edge_index = edge_index.tolist()
mean_ = np.array(edge_index)[:,2].mean()
selected_edges = [(int(row[0]), int(row[1])) for row in edge_index if row[2] > mean_]
edge_index_selected = torch.tensor(selected_edges, dtype=torch.long).t()
edge_index_selected.shape
selected_indices1 = df50[df50['cc_num'] == c_sample].index
is_fraud_values1 = df50.loc[selected_indices1, 'is_fraud'].tolist()
# 두 번째 데이터 선택
# selected_indices2 = df50[df50['cc_num'] == 4.2929e+18].index
# is_fraud_values2 = df50.loc[selected_indices2, 'is_fraud'].tolist()
x = df50.loc[selected_indices1, 'amt'].tolist()
y = df50.loc[selected_indices1, 'is_fraud'].tolist()
g = torch_geometric.data.Data(
edge_index = edge_index_selected,
x = df50.loc[selected_indices1, 'amt'].tolist(),
y = df50.loc[selected_indices1, 'is_fraud'].tolist()
)
unique_nodes = set(g.edge_index.reshape(-1).tolist())
dict_map = {n:i for i,n in enumerate(unique_nodes)}
source, target = edge_index_selected
edge_index_selected2 = torch.tensor([[dict_map[s] for s in source.tolist()],[dict_map[t] for t in target.tolist()]])
g = torch_geometric.data.Data(
edge_index = edge_index_selected2,
x = df50.loc[selected_indices1, 'amt'].tolist(),
y = df50.loc[selected_indices1, 'is_fraud'].tolist()
)
dr_opts = {
'output_size': (500,500)
}
graft.graph.plot_undirected_unweighted(
g,
node_color=g.y,
node_size=g.x,
draw_options= dr_opts
)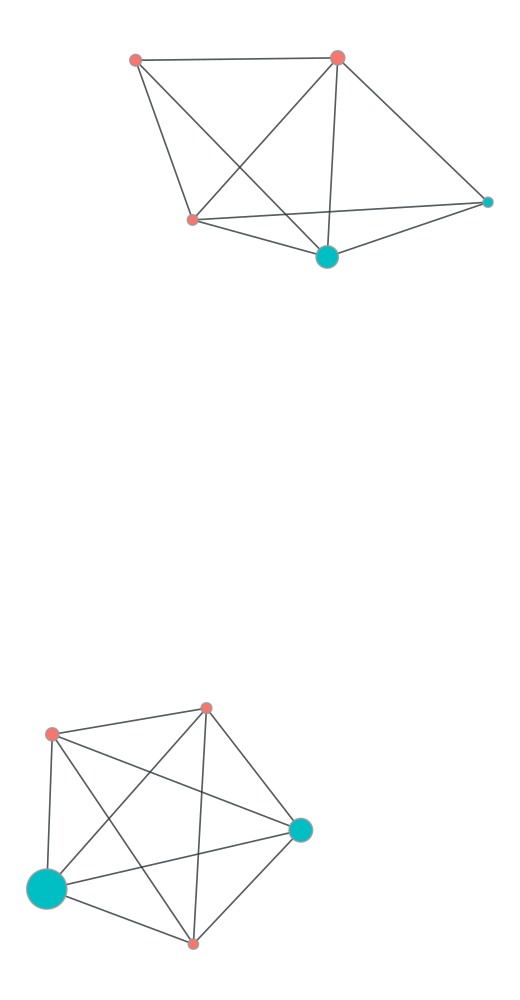
??
c_sample = 5.020500e+11groups = df50[df50['cc_num'] == c_sample]
def compute_time_difference(group):
n = len(group)
result = []
for i in range(n):
for j in range(n):
time_difference = abs(group.iloc[i].trans_date_trans_time.value - group.iloc[j].trans_date_trans_time.value)
result.append([group.iloc[i].name, group.iloc[j].name, time_difference])
return result
edge_index = compute_time_difference(groups)
edge_index = (np.array(edge_index)).astype(np.float64)
theta = edge_index[:,2].mean()
edge_index[:,2] = (np.exp(-edge_index[:,2]/theta)!= 1)*(np.exp(-edge_index[:,2]/theta))
edge_index = edge_index.tolist()
mean_ = np.array(edge_index)[:,2].mean()
selected_edges = [(int(row[0]), int(row[1])) for row in edge_index if row[2] > mean_]
edge_index_selected = torch.tensor(selected_edges, dtype=torch.long).t()
edge_index_selected.shape
selected_indices1 = df50[df50['cc_num'] == c_sample].index
is_fraud_values1 = df50.loc[selected_indices1, 'is_fraud'].tolist()
# 두 번째 데이터 선택
# selected_indices2 = df50[df50['cc_num'] == 4.2929e+18].index
# is_fraud_values2 = df50.loc[selected_indices2, 'is_fraud'].tolist()
x = df50.loc[selected_indices1, 'amt'].tolist()
y = df50.loc[selected_indices1, 'is_fraud'].tolist()
g = torch_geometric.data.Data(
edge_index = edge_index_selected,
x = df50.loc[selected_indices1, 'amt'].tolist(),
y = df50.loc[selected_indices1, 'is_fraud'].tolist()
)
unique_nodes = set(g.edge_index.reshape(-1).tolist())
dict_map = {n:i for i,n in enumerate(unique_nodes)}
source, target = edge_index_selected
edge_index_selected2 = torch.tensor([[dict_map[s] for s in source.tolist()],[dict_map[t] for t in target.tolist()]])
g = torch_geometric.data.Data(
edge_index = edge_index_selected2,
x = df50.loc[selected_indices1, 'amt'].tolist(),
y = df50.loc[selected_indices1, 'is_fraud'].tolist()
)
dr_opts = {
'output_size': (500,500)
}
graft.graph.plot_undirected_unweighted(
g,
node_color=g.y,
node_size=g.x,
draw_options= dr_opts
)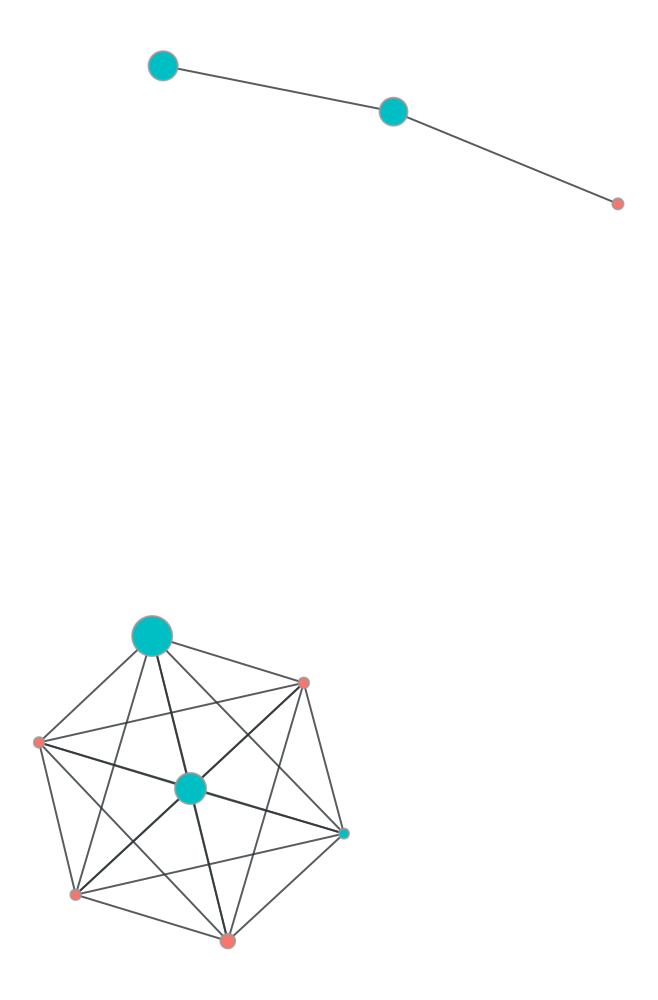
df50[df50.cc_num.apply(int) == 4.503100e+18]| index | trans_date_trans_time | cc_num | merchant | category | amt | first | last | gender | street | ... | lat | long | city_pop | job | dob | trans_num | unix_time | merch_lat | merch_long | is_fraud | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 5381 | 949044 | 2020-01-15 02:04:00 | 4.503100e+18 | fraud_Schumm, Bauch and Ondricka | grocery_pos | 332.10 | Katherine | Tucker | F | 670 Le Meadows Suite 250 | ... | 27.9865 | -82.0139 | 237282 | Clothing/textile technologist | 1979-07-03 | 866751490a47e75897fb852fcf3684a5 | 1358215494 | 28.306661 | -81.336753 | 1 |
| 5382 | 949085 | 2020-01-15 03:13:00 | 4.503100e+18 | fraud_Cremin, Hamill and Reichel | misc_pos | 8.96 | Katherine | Tucker | F | 670 Le Meadows Suite 250 | ... | 27.9865 | -82.0139 | 237282 | Clothing/textile technologist | 1979-07-03 | ad9d834d20eaa6c385e2da4ca8122f08 | 1358219588 | 28.258438 | -81.382080 | 1 |
| 7996 | 876537 | 2019-12-21 17:39:00 | 4.503100e+18 | fraud_Kihn, Brakus and Goyette | personal_care | 19.74 | Katherine | Tucker | F | 670 Le Meadows Suite 250 | ... | 27.9865 | -82.0139 | 237282 | Clothing/textile technologist | 1979-07-03 | 806463bc8f21d4ede724ee50f5a209bc | 1356111580 | 27.037246 | -81.384770 | 0 |
| 8217 | 815021 | 2019-12-07 23:22:00 | 4.503100e+18 | fraud_Pouros-Haag | shopping_pos | 5.76 | Katherine | Tucker | F | 670 Le Meadows Suite 250 | ... | 27.9865 | -82.0139 | 237282 | Clothing/textile technologist | 1979-07-03 | 1e28476a15ad9ed769d0d71d6cc3eb02 | 1354922529 | 28.636698 | -82.419218 | 0 |
| 9176 | 921518 | 2019-12-30 22:32:00 | 4.503100e+18 | fraud_Schroeder Group | health_fitness | 38.49 | Katherine | Tucker | F | 670 Le Meadows Suite 250 | ... | 27.9865 | -82.0139 | 237282 | Clothing/textile technologist | 1979-07-03 | 83cfa21de5d1366a0723351a291f761e | 1356906720 | 27.997746 | -82.168664 | 0 |
| 10248 | 418508 | 2019-07-07 18:01:00 | 4.503100e+18 | fraud_Boyer PLC | shopping_net | 3.49 | Katherine | Tucker | F | 670 Le Meadows Suite 250 | ... | 27.9865 | -82.0139 | 237282 | Clothing/textile technologist | 1979-07-03 | 453f3e6eece7279bea060dc58b765d3f | 1341684100 | 28.687747 | -82.120574 | 0 |
| 10517 | 636869 | 2019-09-28 13:23:00 | 4.503100e+18 | fraud_Ruecker, Beer and Collier | shopping_net | 67.81 | Katherine | Tucker | F | 670 Le Meadows Suite 250 | ... | 27.9865 | -82.0139 | 237282 | Clothing/textile technologist | 1979-07-03 | 46925141500a5774537115173f74e084 | 1348838599 | 27.360343 | -83.002864 | 0 |
| 10613 | 138138 | 2019-03-16 21:05:00 | 4.503100e+18 | fraud_Turner and Sons | shopping_pos | 291.51 | Katherine | Tucker | F | 670 Le Meadows Suite 250 | ... | 27.9865 | -82.0139 | 237282 | Clothing/textile technologist | 1979-07-03 | 680af7c15f20b6b0e3a4acf28c8ee306 | 1331931943 | 28.430308 | -81.703027 | 0 |
| 10950 | 255886 | 2019-05-07 07:46:00 | 4.503100e+18 | fraud_Stracke-Lemke | grocery_pos | 213.37 | Katherine | Tucker | F | 670 Le Meadows Suite 250 | ... | 27.9865 | -82.0139 | 237282 | Clothing/textile technologist | 1979-07-03 | 297be021b9b297f7857a29053a41c903 | 1336376769 | 27.211371 | -81.875982 | 0 |
| 11321 | 611610 | 2019-09-16 16:54:00 | 4.503100e+18 | fraud_Heathcote LLC | shopping_net | 9.51 | Katherine | Tucker | F | 670 Le Meadows Suite 250 | ... | 27.9865 | -82.0139 | 237282 | Clothing/textile technologist | 1979-07-03 | 6705120619ad8b218cdb5dad91628cc5 | 1347814458 | 28.862677 | -82.120978 | 0 |
10 rows × 23 columns
c_sample = 4.503100e+18groups = df50[df50['cc_num'] == c_sample]
def compute_time_difference(group):
n = len(group)
result = []
for i in range(n):
for j in range(n):
time_difference = abs(group.iloc[i].trans_date_trans_time.value - group.iloc[j].trans_date_trans_time.value)
result.append([group.iloc[i].name, group.iloc[j].name, time_difference])
return result
edge_index = compute_time_difference(groups)
edge_index = (np.array(edge_index)).astype(np.float64)
theta = edge_index[:,2].mean()
edge_index[:,2] = (np.exp(-edge_index[:,2]/theta)!= 1)*(np.exp(-edge_index[:,2]/theta))
edge_index = edge_index.tolist()
np.array(edge_index)[:,:2] # edge!!
np.array(edge_index)[:,-1] # weight
selected_indices1 = df50[df50['cc_num'] == c_sample].index
is_fraud_values1 = df50.loc[selected_indices1, 'is_fraud'].tolist()
x = df50.loc[selected_indices1, 'amt'].tolist()
y = df50.loc[selected_indices1, 'is_fraud'].tolist()
g = torch_geometric.data.Data(
edge_index = np.array(edge_index)[:,:2],
edge_attr = np.array(edge_index)[:,-1], # weight
x = df50.loc[selected_indices1, 'amt'].tolist(),
y = df50.loc[selected_indices1, 'is_fraud'].tolist()
)
unique_nodes = set(g.edge_index.reshape(-1).tolist())
dict_map = {n:i for i,n in enumerate(unique_nodes)}
source, target = np.array(edge_index)[:,0], np.array(edge_index)[:,1]
edge_index_selected2 = torch.tensor([[dict_map[s] for s in source.tolist()],[dict_map[t] for t in target.tolist()]])
g = torch_geometric.data.Data(
edge_index = edge_index_selected2,
edge_attr = np.array(edge_index)[:,-1],
x = df50.loc[selected_indices1, 'amt'].tolist(),
y = df50.loc[selected_indices1, 'is_fraud'].tolist()
)
dr_opts = {
'output_size': (200,200),
'edge_marker_size': 1,
'output':f"ten-nodes-{c_sample}.pdf",
}
graft.graph.plot_undirected_weighted(
g,
node_color=g.y,
node_size=g.x,
edge_weight_text=False,
draw_options= dr_opts,
)
c_sample = 6.511350e+15groups = df50[df50['cc_num'] == c_sample]
def compute_time_difference(group):
n = len(group)
result = []
for i in range(n):
for j in range(n):
time_difference = abs(group.iloc[i].trans_date_trans_time.value - group.iloc[j].trans_date_trans_time.value)
result.append([group.iloc[i].name, group.iloc[j].name, time_difference])
return result
edge_index = compute_time_difference(groups)
edge_index = (np.array(edge_index)).astype(np.float64)
theta = edge_index[:,2].mean()
edge_index[:,2] = (np.exp(-edge_index[:,2]/theta)!= 1)*(np.exp(-edge_index[:,2]/theta))
edge_index = edge_index.tolist()
np.array(edge_index)[:,:2] # edge!!
np.array(edge_index)[:,-1] # weight
selected_indices1 = df50[df50['cc_num'] == c_sample].index
is_fraud_values1 = df50.loc[selected_indices1, 'is_fraud'].tolist()
x = df50.loc[selected_indices1, 'amt'].tolist()
y = df50.loc[selected_indices1, 'is_fraud'].tolist()
g = torch_geometric.data.Data(
edge_index = np.array(edge_index)[:,:2],
edge_attr = np.array(edge_index)[:,-1], # weight
x = df50.loc[selected_indices1, 'amt'].tolist(),
y = df50.loc[selected_indices1, 'is_fraud'].tolist()
)
unique_nodes = set(g.edge_index.reshape(-1).tolist())
dict_map = {n:i for i,n in enumerate(unique_nodes)}
source, target = np.array(edge_index)[:,0], np.array(edge_index)[:,1]
edge_index_selected2 = torch.tensor([[dict_map[s] for s in source.tolist()],[dict_map[t] for t in target.tolist()]])
g = torch_geometric.data.Data(
edge_index = edge_index_selected2,
edge_attr = np.array(edge_index)[:,-1],
x = df50.loc[selected_indices1, 'amt'].tolist(),
y = df50.loc[selected_indices1, 'is_fraud'].tolist()
)
dr_opts = {
'output_size': (500,500)
}
graft.graph.plot_undirected_weighted(
g,
node_color=g.y,
node_size=g.x,
edge_weight_text=False,
draw_options= dr_opts
)
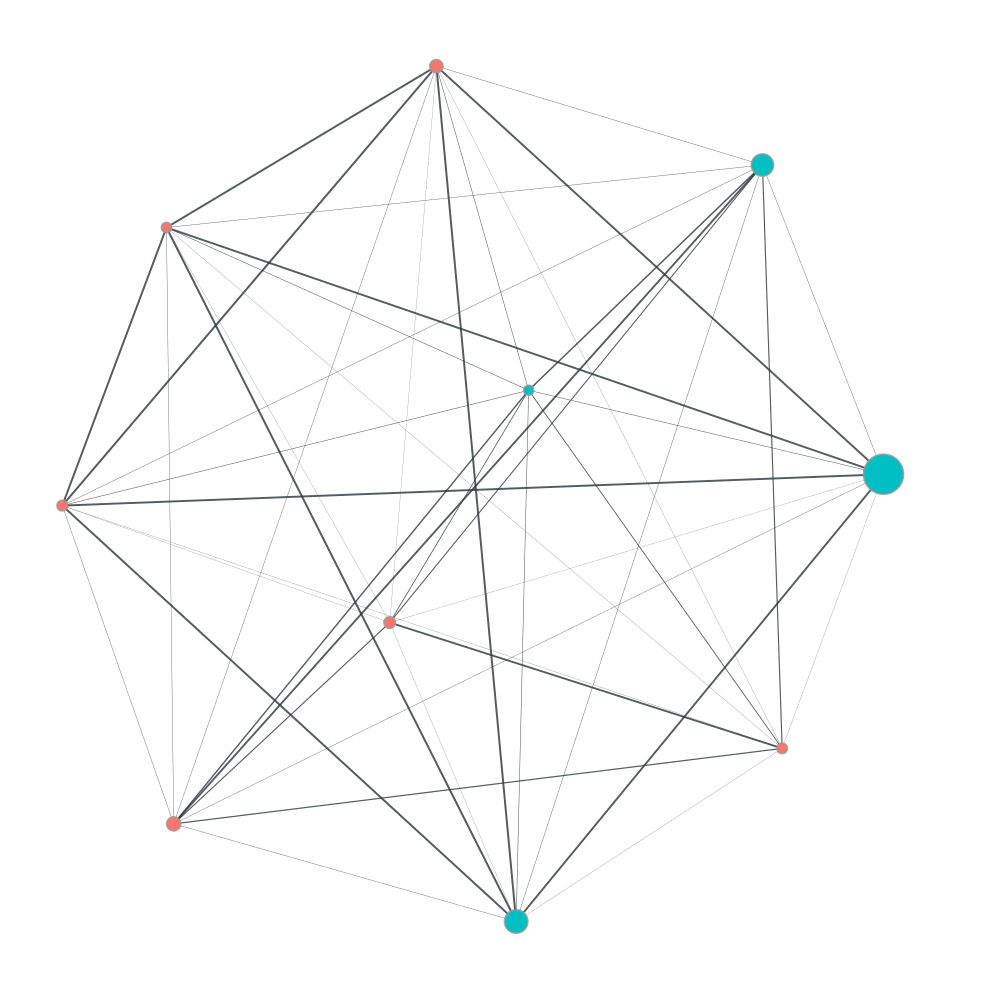
int(4.503100e+18)4503100000000000000pdf! (node10) cc_num = 4.503100e+18
# import importlib
# # importlib을 사용하여 모듈 다시 로드
# importlib.reload(graft)c_sample = 4.503100e+18groups = df50[df50['cc_num'] == c_sample]
def compute_time_difference(group):
n = len(group)
result = []
for i in range(n):
for j in range(n):
time_difference = abs(group.iloc[i].trans_date_trans_time.value - group.iloc[j].trans_date_trans_time.value)
result.append([group.iloc[i].name, group.iloc[j].name, time_difference])
return result
edge_index = compute_time_difference(groups)
edge_index = (np.array(edge_index)).astype(np.float64)
edge_index = np.array(edge_index)[np.array(edge_index)[:,0] != np.array(edge_index)[:,1]]
theta = edge_index[:,2].mean()
edge_index[:,2] = (np.exp(-edge_index[:,2]/theta*9)!= 1)*(np.exp(-edge_index[:,2]/theta*9))
edge_index = edge_index.tolist()
selected_indices1 = df50[df50['cc_num'] == c_sample].index
is_fraud_values1 = df50.loc[selected_indices1, 'is_fraud'].tolist()
g = torch_geometric.data.Data(
edge_index = np.array(edge_index)[:,:2],
edge_attr = np.array(edge_index)[:,-1], # weight
x = df50.loc[selected_indices1, 'amt'].tolist(),
y = df50.loc[selected_indices1, 'is_fraud'].tolist()
)
unique_nodes = set(g.edge_index.reshape(-1).tolist())
dict_map = {n:i for i,n in enumerate(unique_nodes)}
source, target = np.array(edge_index)[:,0], np.array(edge_index)[:,1]
edge_index_selected2 = torch.tensor([[dict_map[s] for s in source.tolist()],[dict_map[t] for t in target.tolist()]])
g = torch_geometric.data.Data(
edge_index = edge_index_selected2,
edge_attr = np.array(edge_index)[:,-1],
x = df50.loc[selected_indices1, 'amt'].tolist(),
y = df50.loc[selected_indices1, 'is_fraud'].tolist()
)
dr_opts = {
'output_size': (150,150),
'edge_marker_size': 1,
'output':"ten-nodes.pdf",
}
graft.graph.plot_undirected_weighted(
g,
node_color=g.y,
node_size=g.x,
edge_weight_text=False,
edge_weight_width_scale=3.0,
draw_options= dr_opts,
)
pdf! (node10) cc_num = 4.809700e+12
c_sample = 4.809700e+12
groups = df50[df50['cc_num'] == c_sample]
def compute_time_difference(group):
n = len(group)
result = []
for i in range(n):
for j in range(n):
time_difference = abs(group.iloc[i].trans_date_trans_time.value - group.iloc[j].trans_date_trans_time.value)
result.append([group.iloc[i].name, group.iloc[j].name, time_difference])
return result
edge_index = compute_time_difference(groups)
edge_index = (np.array(edge_index)).astype(np.float64)
edge_index = np.array(edge_index)[np.array(edge_index)[:,0] != np.array(edge_index)[:,1]]
theta = edge_index[:,2].mean()
edge_index[:,2] = (np.exp(-edge_index[:,2]/theta*9)!= 1)*(np.exp(-edge_index[:,2]/theta*9))
edge_index = edge_index.tolist()
selected_indices1 = df50[df50['cc_num'] == c_sample].index
is_fraud_values1 = df50.loc[selected_indices1, 'is_fraud'].tolist()
g = torch_geometric.data.Data(
edge_index = np.array(edge_index)[:,:2],
edge_attr = np.array(edge_index)[:,-1], # weight
x = df50.loc[selected_indices1, 'amt'].tolist(),
y = df50.loc[selected_indices1, 'is_fraud'].tolist()
)
unique_nodes = set(g.edge_index.reshape(-1).tolist())
dict_map = {n:i for i,n in enumerate(unique_nodes)}
source, target = np.array(edge_index)[:,0], np.array(edge_index)[:,1]
edge_index_selected2 = torch.tensor([[dict_map[s] for s in source.tolist()],[dict_map[t] for t in target.tolist()]])
g = torch_geometric.data.Data(
edge_index = edge_index_selected2,
edge_attr = np.array(edge_index)[:,-1],
x = df50.loc[selected_indices1, 'amt'].tolist(),
y = df50.loc[selected_indices1, 'is_fraud'].tolist()
)
dr_opts = {
'output_size': (150,150),
'edge_marker_size': 1,
'output':"ten-nodes.pdf",
}
graft.graph.plot_undirected_weighted(
g,
node_color=g.y,
node_size=g.x,
edge_weight_text=False,
edge_weight_width_scale=3.0,
draw_options= dr_opts,
)
pdf! (node10) cc_num = 6.511350e+15
c_sample = 6.511350e+15
groups = df50[df50['cc_num'] == c_sample]
def compute_time_difference(group):
n = len(group)
result = []
for i in range(n):
for j in range(n):
time_difference = abs(group.iloc[i].trans_date_trans_time.value - group.iloc[j].trans_date_trans_time.value)
result.append([group.iloc[i].name, group.iloc[j].name, time_difference])
return result
edge_index = compute_time_difference(groups)
edge_index = (np.array(edge_index)).astype(np.float64)
edge_index = np.array(edge_index)[np.array(edge_index)[:,0] != np.array(edge_index)[:,1]]
theta = edge_index[:,2].mean()
edge_index[:,2] = (np.exp(-edge_index[:,2]/theta*9)!= 1)*(np.exp(-edge_index[:,2]/theta*9))
edge_index = edge_index.tolist()
selected_indices1 = df50[df50['cc_num'] == c_sample].index
is_fraud_values1 = df50.loc[selected_indices1, 'is_fraud'].tolist()
g = torch_geometric.data.Data(
edge_index = np.array(edge_index)[:,:2],
edge_attr = np.array(edge_index)[:,-1], # weight
x = df50.loc[selected_indices1, 'amt'].tolist(),
y = df50.loc[selected_indices1, 'is_fraud'].tolist()
)
unique_nodes = set(g.edge_index.reshape(-1).tolist())
dict_map = {n:i for i,n in enumerate(unique_nodes)}
source, target = np.array(edge_index)[:,0], np.array(edge_index)[:,1]
edge_index_selected2 = torch.tensor([[dict_map[s] for s in source.tolist()],[dict_map[t] for t in target.tolist()]])
g = torch_geometric.data.Data(
edge_index = edge_index_selected2,
edge_attr = np.array(edge_index)[:,-1],
x = df50.loc[selected_indices1, 'amt'].tolist(),
y = df50.loc[selected_indices1, 'is_fraud'].tolist()
)
dr_opts = {
'output_size': (150,150),
'edge_marker_size': 1,
'output':"ten-nodes.pdf",
}
graft.graph.plot_undirected_weighted(
g,
node_color=g.y,
node_size=g.x,
edge_weight_text=False,
edge_weight_width_scale=3.0,
draw_options= dr_opts,
)
pdf! (node10) cc_num = 5.020500e+11
c_sample = 5.020500e+11
groups = df50[df50['cc_num'] == c_sample]
def compute_time_difference(group):
n = len(group)
result = []
for i in range(n):
for j in range(n):
time_difference = abs(group.iloc[i].trans_date_trans_time.value - group.iloc[j].trans_date_trans_time.value)
result.append([group.iloc[i].name, group.iloc[j].name, time_difference])
return result
edge_index = compute_time_difference(groups)
edge_index = (np.array(edge_index)).astype(np.float64)
edge_index = np.array(edge_index)[np.array(edge_index)[:,0] != np.array(edge_index)[:,1]]
theta = edge_index[:,2].mean()
edge_index[:,2] = (np.exp(-edge_index[:,2]/theta*9)!= 1)*(np.exp(-edge_index[:,2]/theta*9))
edge_index = edge_index.tolist()
selected_indices1 = df50[df50['cc_num'] == c_sample].index
is_fraud_values1 = df50.loc[selected_indices1, 'is_fraud'].tolist()
g = torch_geometric.data.Data(
edge_index = np.array(edge_index)[:,:2],
edge_attr = np.array(edge_index)[:,-1], # weight
x = df50.loc[selected_indices1, 'amt'].tolist(),
y = df50.loc[selected_indices1, 'is_fraud'].tolist()
)
unique_nodes = set(g.edge_index.reshape(-1).tolist())
dict_map = {n:i for i,n in enumerate(unique_nodes)}
source, target = np.array(edge_index)[:,0], np.array(edge_index)[:,1]
edge_index_selected2 = torch.tensor([[dict_map[s] for s in source.tolist()],[dict_map[t] for t in target.tolist()]])
g = torch_geometric.data.Data(
edge_index = edge_index_selected2,
edge_attr = np.array(edge_index)[:,-1],
x = df50.loc[selected_indices1, 'amt'].tolist(),
y = df50.loc[selected_indices1, 'is_fraud'].tolist()
)
dr_opts = {
'output_size': (150,150),
'edge_marker_size': 1,
'output':"ten-nodes.pdf",
}
graft.graph.plot_undirected_weighted(
g,
node_color=g.y,
node_size=g.x,
edge_weight_text=False,
edge_weight_width_scale=3.0,
draw_options= dr_opts,
)
pdf하나더
# import importlib
# importlib.reload(graft)c_sample = 2.720010e+15groups = df50[df50['cc_num'] == c_sample]
def compute_time_difference(group):
n = len(group)
result = []
for i in range(n):
for j in range(n):
time_difference = abs(group.iloc[i].trans_date_trans_time.value - group.iloc[j].trans_date_trans_time.value)
result.append([group.iloc[i].name, group.iloc[j].name, time_difference])
return result
edge_index = compute_time_difference(groups)
edge_index = (np.array(edge_index)).astype(np.float64)
edge_index = np.array(edge_index)[np.array(edge_index)[:,0] != np.array(edge_index)[:,1]]
theta = edge_index[:,2].mean()
edge_index[:,2] = (np.exp(-edge_index[:,2]/theta)!= 1)*(np.exp(-edge_index[:,2]/theta))
edge_index = edge_index.tolist()
selected_indices1 = df50[df50['cc_num'] == c_sample].index
is_fraud_values1 = df50.loc[selected_indices1, 'is_fraud'].tolist()
g = torch_geometric.data.Data(
edge_index = np.array(edge_index)[:,:2],
edge_attr = np.array(edge_index)[:,-1], # weight
x = df50.loc[selected_indices1, 'amt'].tolist(),
y = df50.loc[selected_indices1, 'is_fraud'].tolist()
)
unique_nodes = set(g.edge_index.reshape(-1).tolist())
dict_map = {n:i for i,n in enumerate(unique_nodes)}
source, target = np.array(edge_index)[:,0], np.array(edge_index)[:,1]
edge_index_selected2 = torch.tensor([[dict_map[s] for s in source.tolist()],[dict_map[t] for t in target.tolist()]])
g = torch_geometric.data.Data(
edge_index = edge_index_selected2,
edge_attr = np.array(edge_index)[:,-1],
x = df50.loc[selected_indices1, 'amt'].tolist(),
y = df50.loc[selected_indices1, 'is_fraud'].tolist()
)
dr_opts = {
'output_size': (500,500),
'edge_marker_size': 1,
#'output':"ten-nodes.pdf",
}
graft.graph.plot_undirected_weighted(
g,
node_color=g.y,
node_size=g.x,
edge_weight_text=False,
draw_options= dr_opts,
)

pdf?
# def graph_sample(df, c_sample):
# def compute_time_difference(group):
# n = len(group)
# result = []
# for i in range(n):
# for j in range(n):
# time_difference = abs(group.iloc[i].trans_date_trans_time.value - group.iloc[j].trans_date_trans_time.value)
# result.append([group.iloc[i].name, group.iloc[j].name, time_difference])
# return result
# groups = df[df['cc_num'] == c_sample]
# edge_index = compute_time_difference(groups)
# edge_index = (np.array(edge_index)).astype(np.float64)
# edge_index = np.array(edge_index)[np.array(edge_index)[:,0] != np.array(edge_index)[:,1]]
# theta = edge_index[:,2].mean()
# edge_index[:,2] = (np.exp(-edge_index[:,2]/theta)!= 1)*(np.exp(-edge_index[:,2]/theta))
# edge_index = edge_index.tolist()
# selected_indices = df[df['cc_num'] == c_sample].index
# g = data.Data(
# edge_index=torch.tensor(edge_index)[:, :2],
# edge_attr=torch.tensor(edge_index)[:, -1],
# x=df.loc[selected_indices, 'amt'].tolist(),
# y=df.loc[selected_indices, 'is_fraud'].tolist()
# )
# unique_nodes = set(g.edge_index.reshape(-1).tolist())
# dict_map = {n: i for i, n in enumerate(unique_nodes)}
# source, target = np.array(edge_index)[:, 0], np.array(edge_index)[:, 1]
# edge_index_selected = torch.tensor([[dict_map[s] for s in source.tolist()], [dict_map[t] for t in target.tolist()]])
# g = data.Data(
# edge_index=edge_index_selected,
# edge_attr=torch.tensor(edge_index)[:, -1],
# x=df.loc[selected_indices, 'amt'].tolist(),
# y=df.loc[selected_indices, 'is_fraud'].tolist()
# )
# dr_opts = {'output_size': (500, 500)}
# plt.figure(figsize=dr_opts['output_size'])
# graft.graph.plot_undirected_weighted(
# g,
# node_color=g.y,
# node_size=g.x,
# edge_weight_text=False,
# draw_options=dr_opts
# )
# return pltdf50['cc_num'].value_counts()cc_num
4.302480e+15 43
1.800650e+14 36
2.131740e+14 35
2.720430e+15 34
2.242540e+15 33
..
3.885950e+13 1
4.026220e+12 1
6.526450e+15 1
4.972230e+15 1
6.535330e+15 1
Name: count, Length: 932, dtype: int64c_sample = 4.302480e+15groups = df50[df50['cc_num'] == c_sample]
def compute_time_difference(group):
n = len(group)
result = []
for i in range(n):
for j in range(n):
time_difference = abs(group.iloc[i].trans_date_trans_time.value - group.iloc[j].trans_date_trans_time.value)
result.append([group.iloc[i].name, group.iloc[j].name, time_difference])
return result
edge_index = compute_time_difference(groups)
edge_index = (np.array(edge_index)).astype(np.float64)
edge_index = np.array(edge_index)[np.array(edge_index)[:,0] != np.array(edge_index)[:,1]]
theta = edge_index[:,2].mean()
edge_index[:,2] = (np.exp(-edge_index[:,2]/theta)!= 1)*(np.exp(-edge_index[:,2]/theta))
edge_index = edge_index.tolist()
np.array(edge_index)[:,:2] # edge!!
np.array(edge_index)[:,-1] # weight
selected_indices1 = df50[df50['cc_num'] == c_sample].index
is_fraud_values1 = df50.loc[selected_indices1, 'is_fraud'].tolist()
x = df50.loc[selected_indices1, 'amt'].tolist()
y = df50.loc[selected_indices1, 'is_fraud'].tolist()
g = torch_geometric.data.Data(
edge_index = np.array(edge_index)[:,:2],
edge_attr = np.array(edge_index)[:,-1], # weight
x = df50.loc[selected_indices1, 'amt'].tolist(),
y = df50.loc[selected_indices1, 'is_fraud'].tolist()
)
unique_nodes = set(g.edge_index.reshape(-1).tolist())
dict_map = {n:i for i,n in enumerate(unique_nodes)}
source, target = np.array(edge_index)[:,0], np.array(edge_index)[:,1]
edge_index_selected2 = torch.tensor([[dict_map[s] for s in source.tolist()],[dict_map[t] for t in target.tolist()]])
g = torch_geometric.data.Data(
edge_index = edge_index_selected2,
edge_attr = np.array(edge_index)[:,-1],
x = df50.loc[selected_indices1, 'amt'].tolist(),
y = df50.loc[selected_indices1, 'is_fraud'].tolist()
)
dr_opts = {
'output_size': (500,500)
}
graft.graph.plot_undirected_weighted(
g,
node_color=g.y,
node_size=g.x,
edge_weight_text=False,
draw_options= dr_opts
)

cc_num_counts = df50['cc_num'].value_counts()
cc_num_10_nodes = cc_num_counts[cc_num_counts == 20].index.tolist()cc20 = df50[(df50['cc_num'].isin(cc_num_10_nodes))]cc20.groupby("cc_num")['is_fraud'].sum().sort_values()cc_num
3.576430e+15 2
2.131420e+14 3
4.377340e+15 7
4.681700e+12 7
2.233880e+15 7
6.761950e+11 8
2.720010e+15 8
1.800430e+14 8
4.149240e+15 9
4.393520e+12 10
3.770270e+14 10
6.762990e+11 11
6.554250e+15 11
2.291160e+15 12
4.223710e+18 12
4.601640e+12 12
4.198470e+12 12
5.714650e+11 12
3.533800e+15 13
3.003320e+13 13
4.048510e+15 14
5.020130e+11 14
6.042785e+10 14
Name: is_fraud, dtype: int64c_sample = 4.958590e+18