import numpy as np
import pandas as pd
import sklearn.impute
import sklearn.linear_model
import missingno as msno해당 자료는 전북대학교 최규빈 교수님 2023학년도 2학기 빅데이터분석특강 자료임
04wk-016: 타이타닉, 결측치처리+로지스틱
최규빈
2023-09-26
1. 강의영상
https://youtu.be/playlist?list=PLQqh36zP38-z8ceMijNQrcczhH3ocuP1Y&si=UehL2BELwmid586_
2. imports
3. 자료불러오기
- 아래의 코드는 kaggle.json 파일이 셋팅된 codespace 혹은 kaggle.json 파일이 셋팅된 리눅스 컴퓨터가 있는 경우만 사용가능 (이런거 셋팅하는 방법은 대면수업에서 해요)
!kaggle competitions download -c titanic
!unzip titanic.zip -d ./titanic
df_train = pd.read_csv('titanic/train.csv')
df_test = pd.read_csv('titanic/test.csv')
!rm titanic.zip
!rm -rf titanic/Warning: Your Kaggle API key is readable by other users on this system! To fix this, you can run 'chmod 600 /home/coco/.kaggle/kaggle.json'
Downloading titanic.zip to /home/coco/Dropbox/coco/posts/Special Topics in Big Data Analysis2023
0%| | 0.00/34.1k [00:00<?, ?B/s]
100%|██████████████████████████████████████| 34.1k/34.1k [00:00<00:00, 5.46MB/s]
Archive: titanic.zip
inflating: ./titanic/gender_submission.csv
inflating: ./titanic/test.csv
inflating: ./titanic/train.csv - 리눅스서버를 사용할 수 없는 경우 download 후 압축풀어서 사용
df_train = pd.read_csv('~/Desktop/titanic/train.csv')
df_test = pd.read_csv('~/Desktop/titanic/test.csv')4. 결측치 확인 및 처리
A. 결측치 체크
- 결측치확인
df_train.info()<class 'pandas.core.frame.DataFrame'>
RangeIndex: 891 entries, 0 to 890
Data columns (total 12 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 PassengerId 891 non-null int64
1 Survived 891 non-null int64
2 Pclass 891 non-null int64
3 Name 891 non-null object
4 Sex 891 non-null object
5 Age 714 non-null float64
6 SibSp 891 non-null int64
7 Parch 891 non-null int64
8 Ticket 891 non-null object
9 Fare 891 non-null float64
10 Cabin 204 non-null object
11 Embarked 889 non-null object
dtypes: float64(2), int64(5), object(5)
memory usage: 83.7+ KBB. 시각화
msno.matrix(df_train)
# msno.bar(df_train) # 큰 의미 X
# msno.dendrogram(df_train) # 큰 의미 X
# msno.heatmap(df_train) # 큰 의미 X <Axes: >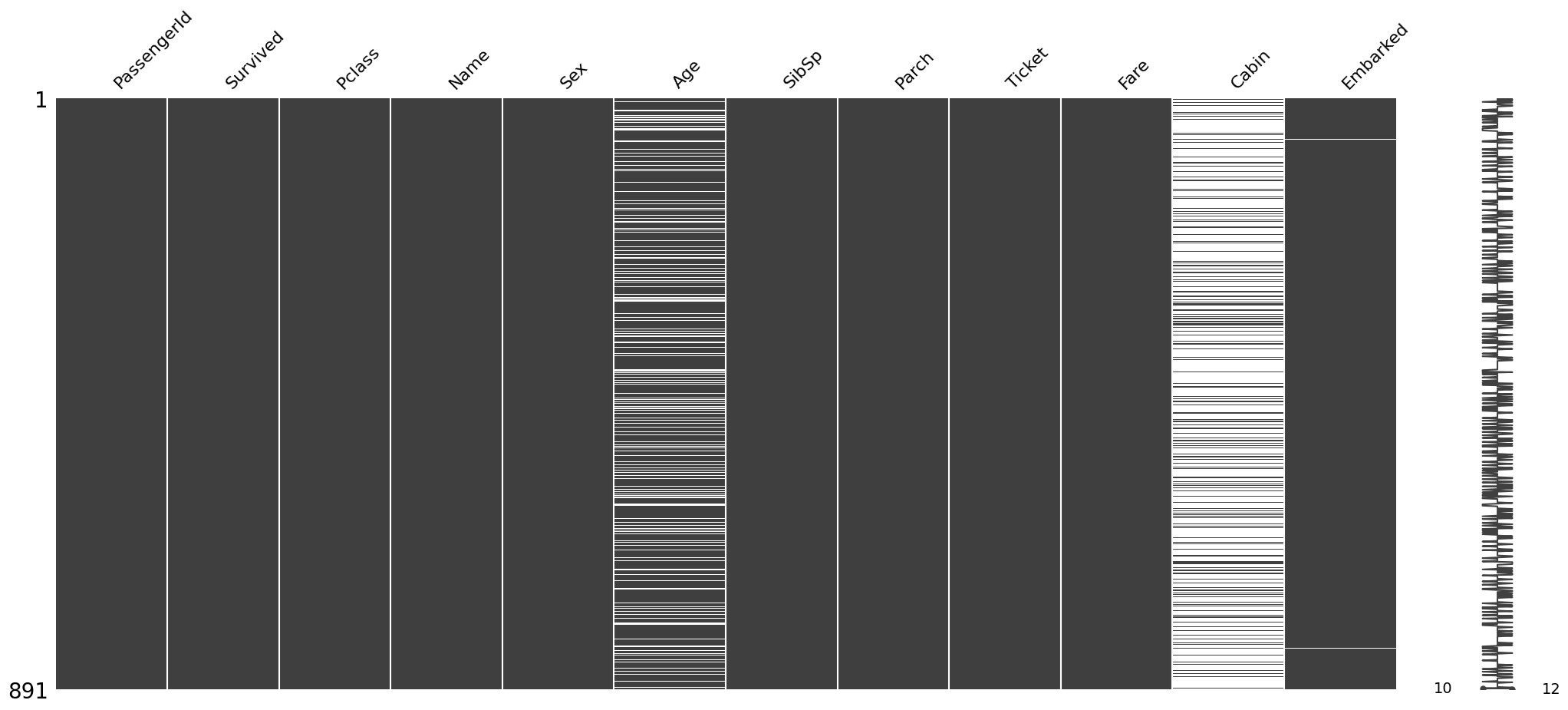
C. 결측치 처리
- 처리 전
df_train.select_dtypes(include="number")| PassengerId | Survived | Pclass | Age | SibSp | Parch | Fare | |
|---|---|---|---|---|---|---|---|
| 0 | 1 | 0 | 3 | 22.0 | 1 | 0 | 7.2500 |
| 1 | 2 | 1 | 1 | 38.0 | 1 | 0 | 71.2833 |
| 2 | 3 | 1 | 3 | 26.0 | 0 | 0 | 7.9250 |
| 3 | 4 | 1 | 1 | 35.0 | 1 | 0 | 53.1000 |
| 4 | 5 | 0 | 3 | 35.0 | 0 | 0 | 8.0500 |
| ... | ... | ... | ... | ... | ... | ... | ... |
| 886 | 887 | 0 | 2 | 27.0 | 0 | 0 | 13.0000 |
| 887 | 888 | 1 | 1 | 19.0 | 0 | 0 | 30.0000 |
| 888 | 889 | 0 | 3 | NaN | 1 | 2 | 23.4500 |
| 889 | 890 | 1 | 1 | 26.0 | 0 | 0 | 30.0000 |
| 890 | 891 | 0 | 3 | 32.0 | 0 | 0 | 7.7500 |
891 rows × 7 columns
def impute_missing(df):
df_imputed = df.copy()
df_num = df.select_dtypes(include="number")
df_cat = df.select_dtypes(exclude="number")
df_imputed[df_num.columns] = sklearn.impute.SimpleImputer().fit_transform(df_num)
df_imputed[df_cat.columns] = sklearn.impute.SimpleImputer(strategy='most_frequent').fit_transform(df_cat)
return df_imputed- 처리 후
impute_missing(df_test)| PassengerId | Pclass | Name | Sex | Age | SibSp | Parch | Ticket | Fare | Cabin | Embarked | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 892.0 | 3.0 | Kelly, Mr. James | male | 34.50000 | 0.0 | 0.0 | 330911 | 7.8292 | B57 B59 B63 B66 | Q |
| 1 | 893.0 | 3.0 | Wilkes, Mrs. James (Ellen Needs) | female | 47.00000 | 1.0 | 0.0 | 363272 | 7.0000 | B57 B59 B63 B66 | S |
| 2 | 894.0 | 2.0 | Myles, Mr. Thomas Francis | male | 62.00000 | 0.0 | 0.0 | 240276 | 9.6875 | B57 B59 B63 B66 | Q |
| 3 | 895.0 | 3.0 | Wirz, Mr. Albert | male | 27.00000 | 0.0 | 0.0 | 315154 | 8.6625 | B57 B59 B63 B66 | S |
| 4 | 896.0 | 3.0 | Hirvonen, Mrs. Alexander (Helga E Lindqvist) | female | 22.00000 | 1.0 | 1.0 | 3101298 | 12.2875 | B57 B59 B63 B66 | S |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 413 | 1305.0 | 3.0 | Spector, Mr. Woolf | male | 30.27259 | 0.0 | 0.0 | A.5. 3236 | 8.0500 | B57 B59 B63 B66 | S |
| 414 | 1306.0 | 1.0 | Oliva y Ocana, Dona. Fermina | female | 39.00000 | 0.0 | 0.0 | PC 17758 | 108.9000 | C105 | C |
| 415 | 1307.0 | 3.0 | Saether, Mr. Simon Sivertsen | male | 38.50000 | 0.0 | 0.0 | SOTON/O.Q. 3101262 | 7.2500 | B57 B59 B63 B66 | S |
| 416 | 1308.0 | 3.0 | Ware, Mr. Frederick | male | 30.27259 | 0.0 | 0.0 | 359309 | 8.0500 | B57 B59 B63 B66 | S |
| 417 | 1309.0 | 3.0 | Peter, Master. Michael J | male | 30.27259 | 1.0 | 1.0 | 2668 | 22.3583 | B57 B59 B63 B66 | C |
418 rows × 11 columns
5. 분석
A. 자료의 정리
{c:len(set(df_train[c])) for c in df_train.select_dtypes(include="object").columns}{'Name': 891, 'Sex': 2, 'Ticket': 681, 'Cabin': 148, 'Embarked': 4}- category 형의 len 조사 똑같은게 몇개 나오는지
X = pd.get_dummies(impute_missing(df_train).drop(['Survived','Name','Ticket','Cabin'],axis=1))
y = impute_missing(df_train)[['Survived']]B. predictor 생성
prdtr = sklearn.linear_model.LogisticRegression()C. 학습
prdtr.fit(X,y)/home/coco/anaconda3/envs/py38/lib/python3.8/site-packages/sklearn/utils/validation.py:1143: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
y = column_or_1d(y, warn=True)
/home/coco/anaconda3/envs/py38/lib/python3.8/site-packages/sklearn/linear_model/_logistic.py:458: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(LogisticRegression()In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook.
On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
LogisticRegression()
D. 예측
prdtr.predict(X)array([0., 1., 1., 1., 0., 0., 0., 0., 1., 1., 1., 1., 0., 0., 1., 1., 0.,
0., 0., 1., 0., 0., 1., 0., 0., 0., 0., 1., 1., 0., 0., 1., 1., 0.,
0., 0., 0., 0., 0., 1., 0., 1., 0., 1., 1., 0., 0., 1., 0., 1., 0.,
0., 1., 1., 0., 0., 1., 0., 1., 0., 0., 1., 0., 0., 0., 0., 1., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 1., 0., 0., 1., 0., 1.,
0., 0., 0., 1., 0., 0., 0., 0., 0., 0., 0., 0., 0., 1., 0., 1., 0.,
0., 0., 0., 0., 1., 0., 0., 1., 0., 1., 0., 1., 1., 0., 0., 0., 1.,
0., 0., 0., 0., 1., 0., 0., 0., 0., 1., 0., 0., 0., 0., 1., 0., 0.,
1., 0., 0., 0., 1., 1., 1., 0., 0., 0., 0., 1., 0., 0., 0., 1., 0.,
0., 0., 0., 1., 0., 0., 0., 0., 1., 0., 0., 0., 0., 1., 0., 0., 0.,
0., 0., 1., 0., 0., 0., 0., 1., 0., 0., 0., 0., 0., 0., 1., 0., 1.,
0., 0., 0., 1., 0., 1., 0., 1., 1., 0., 0., 1., 1., 0., 0., 0., 0.,
0., 1., 0., 0., 1., 0., 0., 1., 0., 0., 0., 1., 1., 0., 1., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 1., 0., 0., 0., 0., 1., 0., 1.,
0., 0., 1., 1., 0., 0., 0., 0., 1., 1., 0., 0., 0., 0., 0., 0., 1.,
1., 1., 1., 1., 1., 0., 0., 0., 0., 1., 0., 0., 0., 1., 1., 0., 0.,
1., 0., 1., 1., 1., 0., 0., 1., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
1., 1., 1., 0., 1., 0., 0., 0., 1., 0., 1., 1., 0., 0., 1., 0., 1.,
1., 1., 0., 1., 1., 1., 1., 0., 0., 1., 1., 0., 1., 1., 0., 0., 1.,
1., 0., 1., 0., 1., 1., 1., 0., 0., 0., 0., 1., 0., 0., 1., 0., 0.,
0., 1., 0., 0., 0., 1., 1., 1., 0., 0., 0., 0., 0., 0., 0., 0., 1.,
1., 1., 1., 0., 0., 1., 0., 0., 0., 1., 1., 1., 1., 0., 0., 0., 1.,
1., 1., 1., 1., 0., 0., 1., 1., 0., 1., 0., 0., 0., 1., 0., 1., 0.,
0., 0., 1., 1., 0., 1., 0., 0., 1., 0., 0., 1., 0., 1., 0., 0., 0.,
0., 0., 0., 0., 1., 0., 0., 1., 1., 1., 0., 1., 0., 0., 0., 1., 0.,
0., 1., 1., 0., 0., 0., 1., 1., 0., 0., 1., 1., 1., 1., 0., 1., 0.,
0., 1., 0., 0., 1., 0., 1., 0., 0., 0., 0., 0., 0., 0., 0., 1., 1.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 1., 0., 0., 1., 1., 1., 0.,
0., 0., 0., 1., 0., 0., 0., 0., 0., 0., 1., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 1., 0., 1., 0., 0., 1., 1., 1., 1., 1., 1., 0., 0., 0.,
0., 0., 0., 1., 0., 0., 1., 0., 1., 0., 1., 0., 0., 1., 0., 0., 1.,
1., 0., 0., 1., 0., 0., 1., 1., 1., 0., 1., 0., 1., 1., 0., 0., 0.,
0., 0., 1., 0., 0., 0., 1., 0., 0., 0., 1., 0., 1., 1., 1., 1., 0.,
0., 0., 0., 1., 0., 0., 1., 0., 0., 0., 1., 0., 1., 0., 0., 1., 1.,
1., 0., 1., 1., 0., 0., 0., 1., 0., 0., 0., 0., 0., 1., 0., 1., 0.,
0., 1., 0., 0., 0., 1., 0., 0., 0., 0., 0., 0., 0., 1., 1., 0., 0.,
1., 0., 0., 1., 0., 1., 1., 0., 0., 0., 0., 0., 0., 0., 0., 1., 0.,
0., 0., 0., 0., 0., 1., 1., 0., 0., 1., 0., 0., 1., 1., 0., 1., 0.,
0., 0., 0., 1., 0., 1., 0., 1., 1., 0., 0., 1., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 1., 1., 0., 0., 0., 0., 0., 0., 1., 0., 1.,
1., 1., 0., 0., 0., 0., 0., 0., 0., 1., 0., 1., 0., 0., 0., 0., 0.,
1., 0., 0., 1., 0., 1., 0., 0., 0., 1., 0., 1., 0., 1., 0., 0., 0.,
0., 0., 1., 1., 0., 0., 1., 0., 0., 0., 0., 0., 1., 1., 0., 1., 1.,
0., 0., 0., 0., 0., 1., 1., 0., 0., 0., 0., 1., 0., 0., 0., 0., 1.,
0., 0., 1., 0., 0., 0., 1., 0., 0., 0., 0., 1., 0., 0., 0., 1., 0.,
1., 0., 1., 0., 0., 0., 0., 1., 0., 1., 0., 0., 1., 0., 1., 1., 1.,
0., 0., 0., 0., 1., 0., 0., 0., 0., 0., 0., 0., 0., 0., 1., 1., 0.,
1., 0., 1., 1., 0., 0., 0., 0., 1., 0., 1., 0., 0., 0., 1., 0., 0.,
1., 0., 0., 0., 1., 0., 0., 1., 0., 0., 0., 0., 0., 1., 1., 0., 0.,
0., 0., 1., 0., 0., 0., 0., 0., 0., 1., 0., 0., 0., 0., 0., 0., 1.,
0., 0., 1., 1., 1., 1., 1., 0., 1., 0., 0., 0., 1., 0., 0., 1., 1.,
0., 0., 0., 0., 1., 0., 0., 1., 1., 0., 0., 0., 1., 1., 0., 1., 0.,
0., 1., 0., 1., 1., 0., 0.])E. 평가
prdtr.score(X,y)0.79910213243546586. HW
위와 동일한 방식으로 test.csv에서의 생존여부를 예측하고 kaggle에 제출
{c:len(set(df_test[c])) for c in df_test.select_dtypes(include="object").columns}{'Name': 418, 'Sex': 2, 'Ticket': 363, 'Cabin': 77, 'Embarked': 3}- category 형의 len 조사 똑같은게 몇개 나오는지
X = pd.get_dummies(impute_missing(df_test).drop(['Name','Ticket','Cabin'],axis=1))X| PassengerId | Pclass | Age | SibSp | Parch | Fare | Sex_female | Sex_male | Embarked_C | Embarked_Q | Embarked_S | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 892.0 | 3.0 | 34.50000 | 0.0 | 0.0 | 7.8292 | 0 | 1 | 0 | 1 | 0 |
| 1 | 893.0 | 3.0 | 47.00000 | 1.0 | 0.0 | 7.0000 | 1 | 0 | 0 | 0 | 1 |
| 2 | 894.0 | 2.0 | 62.00000 | 0.0 | 0.0 | 9.6875 | 0 | 1 | 0 | 1 | 0 |
| 3 | 895.0 | 3.0 | 27.00000 | 0.0 | 0.0 | 8.6625 | 0 | 1 | 0 | 0 | 1 |
| 4 | 896.0 | 3.0 | 22.00000 | 1.0 | 1.0 | 12.2875 | 1 | 0 | 0 | 0 | 1 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 413 | 1305.0 | 3.0 | 30.27259 | 0.0 | 0.0 | 8.0500 | 0 | 1 | 0 | 0 | 1 |
| 414 | 1306.0 | 1.0 | 39.00000 | 0.0 | 0.0 | 108.9000 | 1 | 0 | 1 | 0 | 0 |
| 415 | 1307.0 | 3.0 | 38.50000 | 0.0 | 0.0 | 7.2500 | 0 | 1 | 0 | 0 | 1 |
| 416 | 1308.0 | 3.0 | 30.27259 | 0.0 | 0.0 | 8.0500 | 0 | 1 | 0 | 0 | 1 |
| 417 | 1309.0 | 3.0 | 30.27259 | 1.0 | 1.0 | 22.3583 | 0 | 1 | 1 | 0 | 0 |
418 rows × 11 columns
df_test.assign(Survived=prdtr.predict(X)).loc[:,['PassengerId','Survived']]\
.to_csv("04wk_HW.csv",index=False)- 위 코드는 Survived의 형식이 float라서 kaggle 제출했더니 0점나온듯?
df_test.assign(Survived=prdtr.predict(X).astype(int)).loc[:,['PassengerId','Survived']]\
.to_csv("04wk_HW_.csv",index=False)- kaggle 제출 -> 0.74401