import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import matplotlib.animation
import IPython
import sklearn.tree
#---#
import warnings
warnings.filterwarnings('ignore')15wk-fin
최규빈
2023-12-21
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import sklearn.metrics- 의사결정나무의 수동구현은 위에서 제시된 모듈 (numpy, pandas, sklearn.metrics, matplotlib, seaborn) 만을 사용해야하며 이외의 모듈을 사용할 경우 0점 처리함.
- True/False를 판단하는 문제는 답만 써도 무방함. (이유를 써도 상관없음)
- Treu/False의 판단 문제는 모두 맞출 경우만 정답으로 인정함. 다만 틀린이유가 사소하다고 판단할경우 감점없이 만점처리함.
1. 의사결정나무의 수동구현 (70점)
df_train = pd.read_csv('https://raw.githubusercontent.com/guebin/MP2023/master/posts/height_train.csv')
df_train| weight | sex | height | |
|---|---|---|---|
| 0 | NaN | male | 164.227738 |
| 1 | NaN | male | 165.798660 |
| 2 | 75.219015 | male | 165.528672 |
| 3 | NaN | male | 163.706442 |
| 4 | 81.476750 | male | 165.501403 |
| ... | ... | ... | ... |
| 275 | 49.308558 | female | 148.587771 |
| 276 | NaN | male | 164.822474 |
| 277 | NaN | male | 163.907671 |
| 278 | NaN | male | 161.674476 |
| 279 | 53.714772 | female | 146.775975 |
280 rows × 3 columns
sns.lineplot(df_train, x = df_train['weight'], y = df_train['height'], hue=df_train['sex'])<AxesSubplot: xlabel='weight', ylabel='height'>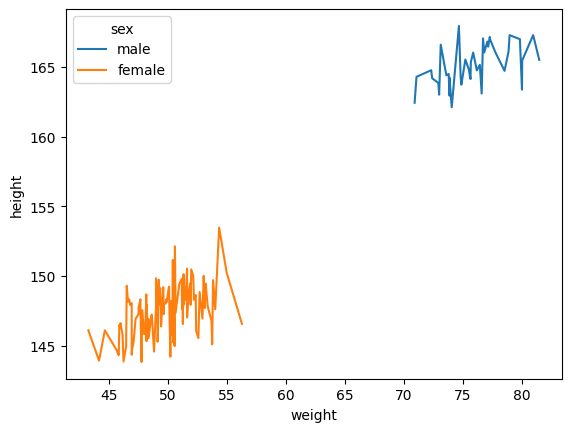
df_train['weight'].mean()56.580501947309074(1) df_train에서 “sex”,“weight”를 설명변수로 “height”을 반응변수로 설정하라. 결측치가 있을 경우 결측값에 일괄적으로 -99로 채워넣어라.
힌트: 결측치를 처리하기 위해 아래의 코드를 관찰하라.
df_toy = pd.DataFrame({'X':[1,2,np.nan,np.nan,5],'y':[3,4,5,1,2]})
df_toy| X | y | |
|---|---|---|
| 0 | 1.0 | 3 |
| 1 | 2.0 | 4 |
| 2 | NaN | 5 |
| 3 | NaN | 1 |
| 4 | 5.0 | 2 |
df_toy.fillna(-99)| X | y | |
|---|---|---|
| 0 | 1.0 | 3 |
| 1 | 2.0 | 4 |
| 2 | -99.0 | 5 |
| 3 | -99.0 | 1 |
| 4 | 5.0 | 2 |
df_tr = df_train.copy()
df_tr.info()<class 'pandas.core.frame.DataFrame'>
RangeIndex: 280 entries, 0 to 279
Data columns (total 3 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 weight 151 non-null float64
1 sex 280 non-null object
2 height 280 non-null float64
dtypes: float64(2), object(1)
memory usage: 6.7+ KBdf_train[df_train['sex'].isin(['female', 'male']) & df_train['weight'].isna()].groupby('sex').size()sex
male 129
dtype: int64- weight에 129개의 결측치가 있고, 다 남자!!
df_tr = df_tr.fillna(-99)
df_tr.info()<class 'pandas.core.frame.DataFrame'>
RangeIndex: 280 entries, 0 to 279
Data columns (total 3 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 weight 280 non-null float64
1 sex 280 non-null object
2 height 280 non-null float64
dtypes: float64(2), object(1)
memory usage: 6.7+ KBX = df_tr[['sex','weight']]y = df_tr['height']X.head()| sex | weight | |
|---|---|---|
| 0 | male | -99.000000 |
| 1 | male | -99.000000 |
| 2 | male | 75.219015 |
| 3 | male | -99.000000 |
| 4 | male | 81.476750 |
y.head()0 164.227738
1 165.798660
2 165.528672
3 163.706442
4 165.501403
Name: height, dtype: float64(2) height열의 평균으로 height의 값을 추정하라. 추정값을 yhat에 저장하라. sklearn.metrics.r2_score()을 이용하여 r2_score를 계산하라.
hint: 0이 나와야 한다.
yhat = ([y.mean()] * len(y))
r2_score = sklearn.metrics.r2_score(y,yhat)
r2_score0.0(3) 아래를 계산하라.
r=y-yhat
여기에서 yhat은 (2)의 결과로 얻어진 적합값을 의미한다. 이제 r에 Weight를 기준으로 의사결정나무를 적용하여 아래와 같은 분할을 만들어라.
X['weight']<cX['weight']>=c
sklearn.metrics.r2_score()를 이용하여 최적의 \(c\)값을 구하여라.
참고
아래의 구간을 적당히 등분하여 구할 것. 너무 세밀하게 등분하지 않아도 무방함.
(X['weight'].min(), X['weight'].max())r = y - yhat
r0 6.241209
1 7.812131
2 7.542143
3 5.719914
4 7.514874
...
275 -9.398757
276 6.835946
277 5.921143
278 3.687948
279 -11.210554
Name: height, Length: 280, dtype: float64- 결측값 고려 안했을 때
def fit_predict(X,y,c):
X = np.array(X['weight']).reshape(-1)
y = np.array(y)
yhat = y*0
yhat[X<c] = y[X<c].mean()
yhat[X>=c] = y[X>=c].mean()
return yhatcuts = np.arange(X['weight'].min(), X['weight'].max(), 0.5).round(2)
score = np.array([sklearn.metrics.r2_score(y,fit_predict(X,y,c)) for c in cuts])pd.DataFrame({'cut':cuts,'score':score})\
.plot.line(x='cut',y='score',backend='plotly')c = 43일 때 score값이 크다, 결측값(-99)의 영향을 많이 받는다.
## step1
X = np.array(df_tr[['weight']])
r = r
## step2
predictr = sklearn.tree.DecisionTreeRegressor(max_depth=2)
## step3
predictr.fit(X,r)
## step4 -- pass
# predictr.predict(X) DecisionTreeRegressor(max_depth=2)In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook.
On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
DecisionTreeRegressor(max_depth=2)
sklearn.tree.plot_tree(predictr)[Text(0.4, 0.8333333333333334, 'x[0] <= -27.858\nsquared_error = 75.768\nsamples = 280\nvalue = 0.0'),
Text(0.2, 0.5, 'squared_error = 2.195\nsamples = 129\nvalue = 6.869'),
Text(0.6, 0.5, 'x[0] <= 63.609\nsquared_error = 63.87\nsamples = 151\nvalue = -5.869'),
Text(0.4, 0.16666666666666666, 'squared_error = 3.374\nsamples = 111\nvalue = -10.55'),
Text(0.8, 0.16666666666666666, 'squared_error = 2.139\nsamples = 40\nvalue = 7.123')]
dftr2 = df_tr[df_tr['weight']>-27.858]## step1
X = pd.get_dummies(dftr2[['weight','sex']])
r = np.array(dftr2['r'])
## step2
predictr = sklearn.tree.DecisionTreeRegressor(max_depth=1)
## step3
predictr.fit(X,r)
## step4 -- pass
# predictr.predict(X) DecisionTreeRegressor(max_depth=1)In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook.
On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
DecisionTreeRegressor(max_depth=1)
sklearn.tree.plot_tree(predictr)[Text(0.5, 0.75, 'x[2] <= 0.5\nsquared_error = 63.87\nsamples = 151\nvalue = -5.869'),
Text(0.25, 0.25, 'squared_error = 3.374\nsamples = 111\nvalue = -10.55'),
Text(0.75, 0.25, 'squared_error = 2.139\nsamples = 40\nvalue = 7.123')]
똑같네..
weight, set depth=2
## step1
X = pd.get_dummies(df_tr[['weight','sex']])
y = y
## step2
predictr = sklearn.tree.DecisionTreeRegressor(max_depth=2, splitter="best")
## step3
predictr.fit(X,y)
## step4 -- pass
# predictr.predict(X) DecisionTreeRegressor(max_depth=2)In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook.
On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
DecisionTreeRegressor(max_depth=2)
sklearn.tree.plot_tree(predictr,feature_names=X.columns)[Text(0.5, 0.8333333333333334, 'sex_female <= 0.5\nsquared_error = 75.768\nsamples = 280\nvalue = 157.987'),
Text(0.25, 0.5, 'weight <= 76.658\nsquared_error = 2.194\nsamples = 169\nvalue = 164.916'),
Text(0.125, 0.16666666666666666, 'squared_error = 2.118\nsamples = 154\nvalue = 164.79'),
Text(0.375, 0.16666666666666666, 'squared_error = 1.125\nsamples = 15\nvalue = 166.212'),
Text(0.75, 0.5, 'weight <= 48.935\nsquared_error = 3.374\nsamples = 111\nvalue = 147.436'),
Text(0.625, 0.16666666666666666, 'squared_error = 2.076\nsamples = 41\nvalue = 146.323'),
Text(0.875, 0.16666666666666666, 'squared_error = 2.984\nsamples = 70\nvalue = 148.088')]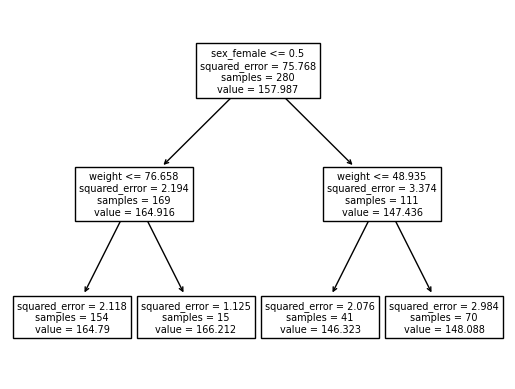
predictr.score(X,y)0.9699722000340028- 결측치가 많아서 < 43 인 것의 height값이 더 큰 값으로 나오네
weight(1번 feature), 그다음은.., depth=2
## step1
X = df_tr[['weight']]
y = df_tr['height']
## step2
predictr = sklearn.tree.DecisionTreeRegressor(max_depth=1)
## step3
predictr.fit(X,y)
## step4 -- pass
# predictr.predict(X)
sklearn.tree.plot_tree(predictr,feature_names=X.columns)[Text(0.5, 0.75, 'weight <= -27.858\nsquared_error = 75.768\nsamples = 280\nvalue = 157.987'),
Text(0.25, 0.25, 'squared_error = 2.195\nsamples = 129\nvalue = 164.856'),
Text(0.75, 0.25, 'squared_error = 63.87\nsamples = 151\nvalue = 152.118')]
predictr.score(X,y)0.5320524394291483condition = df_tr['weight'] > -27.858condition2 = df_tr['weight'] <= -27.858filtered_df = df_tr[condition]filtered_df2 = df_tr[condition2]filtered_df| weight | sex | height | |
|---|---|---|---|
| 2 | 75.219015 | male | 165.528672 |
| 4 | 81.476750 | male | 165.501403 |
| 5 | 51.352066 | female | 150.125995 |
| 6 | 76.715595 | male | 167.036723 |
| 7 | 49.019086 | female | 149.829118 |
| ... | ... | ... | ... |
| 267 | 47.791830 | female | 143.832614 |
| 271 | 46.991268 | female | 144.749219 |
| 274 | 47.287594 | female | 146.931919 |
| 275 | 49.308558 | female | 148.587771 |
| 279 | 53.714772 | female | 146.775975 |
151 rows × 3 columns
## step1
X = pd.get_dummies(filtered_df[['sex','weight']])
y = filtered_df['height']
## step2
predictr = sklearn.tree.DecisionTreeRegressor(max_depth=2,splitter="best")
## step3
predictr.fit(X,y)
## step4 -- pass
# predictr.predict(X)
sklearn.tree.plot_tree(predictr,feature_names=X.columns)[Text(0.5, 0.8333333333333334, 'weight <= 63.609\nsquared_error = 63.87\nsamples = 151\nvalue = 152.118'),
Text(0.25, 0.5, 'weight <= 48.935\nsquared_error = 3.374\nsamples = 111\nvalue = 147.436'),
Text(0.125, 0.16666666666666666, 'squared_error = 2.076\nsamples = 41\nvalue = 146.323'),
Text(0.375, 0.16666666666666666, 'squared_error = 2.984\nsamples = 70\nvalue = 148.088'),
Text(0.75, 0.5, 'weight <= 76.658\nsquared_error = 2.139\nsamples = 40\nvalue = 165.11'),
Text(0.625, 0.16666666666666666, 'squared_error = 1.58\nsamples = 25\nvalue = 164.448'),
Text(0.875, 0.16666666666666666, 'squared_error = 1.125\nsamples = 15\nvalue = 166.212')]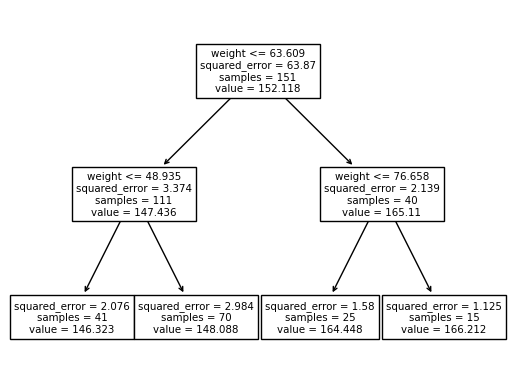
## step1
X = pd.get_dummies(filtered_df2[['sex','weight']])
y = filtered_df2['height']
## step2
predictr = sklearn.tree.DecisionTreeRegressor(max_depth=1)
## step3
predictr.fit(X,y)
## step4 -- pass
# predictr.predict(X)
sklearn.tree.plot_tree(predictr,feature_names=X.columns)[Text(0.5, 0.5, 'squared_error = 2.195\nsamples = 129\nvalue = 164.856')]
weihgt, depth=2
## step1
X = df_tr[['weight']]
y = df_tr['height']
## step2
predictr = sklearn.tree.DecisionTreeRegressor(max_depth=2)
## step3
predictr.fit(X,y)
## step4 -- pass
# predictr.predict(X) DecisionTreeRegressor(max_depth=2)In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook.
On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
DecisionTreeRegressor(max_depth=2)
sklearn.tree.plot_tree(predictr)[Text(0.4, 0.8333333333333334, 'x[0] <= -27.858\nsquared_error = 75.768\nsamples = 280\nvalue = 157.987'),
Text(0.2, 0.5, 'squared_error = 2.195\nsamples = 129\nvalue = 164.856'),
Text(0.6, 0.5, 'x[0] <= 63.609\nsquared_error = 63.87\nsamples = 151\nvalue = 152.118'),
Text(0.4, 0.16666666666666666, 'squared_error = 3.374\nsamples = 111\nvalue = 147.436'),
Text(0.8, 0.16666666666666666, 'squared_error = 2.139\nsamples = 40\nvalue = 165.11')]
(4) (3)의 결과로 얻어진 아래의 분할을 고려하자.
X['weight'] >= c이 분할에서 depth=2 로 나무를 성장하고자 한다. 성장이가능한가? 성장이 가능하다면 이때 나무를 성장시키기 위한 변수로 weigth와 sex중 무엇이 적절한가? 왜 그렇다고 생각하는가?
?sex.
데이터의 46%가 결측값이 있고 해당 값의 성별은 모두 남성이다.
먼저 성별을 통해 나무를 성장시키는 것이 중요하다.
(5) (3)의 결과로 얻어진 아래의 분할을 고려하자.
X['weight'] < c이 분할에서 depth=2 로 나무를 성장하고자 한다. 성장이가능한가? 성장이 가능하다면 이때 나무를 성장시키기 위한 변수로 weigth와 sex중 무엇이 적절한가? 왜 그렇다고 생각하는가?
(6) (3)-(5)의 결과를 이용하여 depth=2인 의사결정나무에 의한 r의 적합값을 구하여라. 이를 이용하여 yhat을 update하라. 이때 학습률은 0.1로 설정하고 업데이트된 결과를 yhat2로 저장하라. 그리고sklearn.metrics.r2_score()을 이용하여 y와 yhat2의 r2_score를 계산하라.
힌트: 아래의 알고리즘이 동치임을 이용하라.
yhat2\(\leftarrow\)yhat+ 학습률 \(\times\)rhatr2\(\leftarrow\)r- 학습률 \(\times\)rhat, wherer2=y-yhat2
yhat2 = yhat + 0.1 * rhatr2 = r - 0.1
r2 = y - yhat2 ?? 뭔솔..(7) (6)에서 학습률이 0.5일 경우 y와 yhat2의 r2_score를 계산하라.
2. 다음을 읽고 참거짓을 판단하라. (30점)
(1) 의사결정나무에서 max_depth의 설정값이 커질수록 오버피팅의 위험이 있다.
T
(2) 배깅의 설명변수중 일부를 drop 하며 나무를 성장시킨다.
(3) 랜덤포레스트는 나무가지를 랜덤으로 성장시키기도 하고 파괴시키기도 한다.
(4) 부스팅은 여러가지 의사결정나무의 적합값을 평균내는 방식으로 최종예측을 한다.
F(배깅)
(5) Accuracy는 분류문제에서 언제나 가장 합리적인 평가지표이다.
F
(6) 모듈49의 아래그림은 “sex == ‘male’” 일 경우 “sex=‘female’” 일때보다 항상(=모든 관측치에 대하여) 키의 예측값을 +2.1 만큼 보정해야 한다는 것을 의미한다.
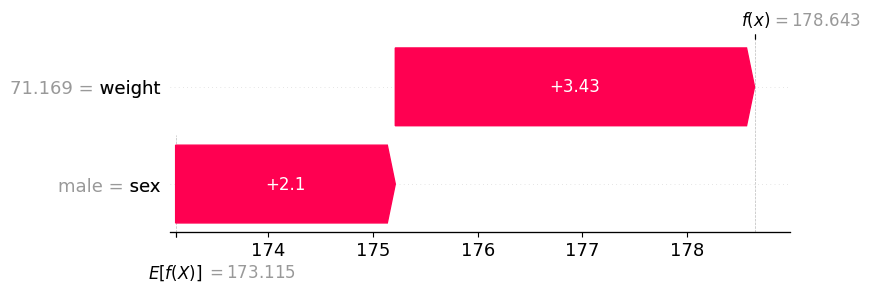
F
(7) 모듈54에서 제시된 아래의 그림은 사실 전혀 고려할 필요가 없다.
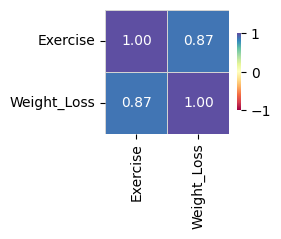
왜냐하면 Exercise는 범주형, Weight_Loss는 연속형이므로 correlation값은 의미가 없기 때문이다.
(8) 시계열분석에서 static_feature란 이미 알고있는 미래의 시계열자료를 의미한다.
F
(9) 모듈59에서 소개된 자전거대여자료와 같이 시간특징이 포함된 자료는 언제나 (과거를 기반으로 미래를 예측하는) 시계열분석을 하는 것이 올바르다.
F
(10) 모듈60에서 소개된 하이퍼파라메터 설정법을 이용하면 때때로 모형의 적합도를 높일 수 있다.
T